RAFAEL
FERREIRA DA SILVA
Group Leader
Senior Research Scientist
Group Leader
Senior Research Scientist
RAFAEL
Ferreira da
Silva
I am the Group Leader for the Workflow and Ecosystem Services (WES) group and a Senior Research Scientist in the National Center for Computational Sciences (NCCS) at Oak Ridge National Laboratory (ORNL). Additionally, I hold an Adjunct Research Assistant Professor position at the University of Southern California (USC) in the Department of Computer Science. I also serve as the Special Content Editor for the Future Generation Computer Systems (FGCS) journal, and I am a Senior Member of IEEE and ACM professional associations.
In my work, I am deeply engaged in the field of parallel and distributed computing systems, with a primary focus on modeling and simulation to enhance and innovate in scientific workflows. My areas of expertise include scheduling, optimization, fault tolerance, and energy efficiency within distributed computing, applying these skills across diverse platforms like clouds, grids, and HPC clusters. This dedication is driven by a commitment to improve the efficiency and resilience of digital infrastructures to meet the ever-changing needs of the scientific community.
Additionally, as the Founder and Executive Director of the Workflows Community Initiative, I am committed to fostering collaboration and advancement in the field of workflows research and development. This initiative plays a crucial role in uniting researchers and professionals to share knowledge and drive innovations in workflow management and applications.
Chair roles in conferences
20PC member in conferences
52Research grants
18Research Projects




 Rafael Ferreira da Silva, Ph.D.
Rafael Ferreira da Silva, Ph.D.Oak Ridge National Laboratory
P.O. Box 2008, Oak Ridge, TN, USA 37831
Office: 865-341-1894
silvarf@ornl.gov
Research Publications
List of peer-reviewed scientific publications
2023
-
Casanova, H., Berney, K., Chastel, S., & Ferreira da Silva, R. (2023). WfCommons: Data Collection and Runtime Experiments using Multiple Workflow Systems. The 1st IEEE International Workshop on Workflows in Distributed Environments (WiDE 2023), 1870–1875. https://doi.org/10.1109/COMPSAC57700.2023.00290
[BibTex]@inproceedings{casanova2023wide, title = {WfCommons: Data Collection and Runtime Experiments using Multiple Workflow Systems}, author = {Casanova, Henri and Berney, Kyle and Chastel, Serge and Ferreira da Silva, Rafael}, booktitle = {The 1st IEEE International Workshop on Workflows in Distributed Environments (WiDE 2023)}, pages = {1870--1875}, year = {2023}, doi = {10.1109/COMPSAC57700.2023.00290} } -
Casanova, H., Wong, Y. C., Pottier, L., & Ferreira da Silva, R. (2023). On the Feasibility of Simulation-driven Portfolio Scheduling for Cyberinfrastructure Runtime Systems. Workshop on Job Scheduling Strategies for Parallel Processing (JSSPP), 3–24. https://doi.org/10.1007/978-3-031-22698-4_1
[BibTex]@inproceedings{casanova2022jsspp, title = {On the Feasibility of Simulation-driven Portfolio Scheduling for Cyberinfrastructure Runtime Systems}, author = {Casanova, Henri and Wong, Yick Ching and Pottier, Loic and Ferreira da Silva, Rafael}, booktitle = {Workshop on Job Scheduling Strategies for Parallel Processing (JSSPP)}, pages = {3--24}, year = {2023}, doi = {10.1007/978-3-031-22698-4_1} } -
Coleman, T., Casanova, H., & Ferreira da Silva, R. (2023). Automated Generation of Scientific Workflow Generators with WfChef. Future Generation Computer Systems, 147, 16–29. https://doi.org/10.1016/j.future.2023.04.031
[BibTex]@article{coleman2023fgcs, title = {Automated Generation of Scientific Workflow Generators with WfChef}, author = {Coleman, Taina and Casanova, Henri and Ferreira da Silva, Rafael}, journal = {Future Generation Computer Systems}, volume = {147}, number = {}, pages = {16--29}, doi = {10.1016/j.future.2023.04.031}, year = {2023} } -
Ferreira da Silva, R., Badia, R. M., Bala, V., Bard, D., Bremer, T., Buckley, I., Caino-Lores, S., Chard, K., Goble, C., Jha, S., Katz, D. S., Laney, D., Parashar, M., Suter, F., Tyler, N., Uram, T., Altintas, I., Andersson, S., Arndt, W., … Zulfiqar, M. (2023). Workflows Community Summit 2022: A Roadmap Revolution (ORNL/TM-2023/2885; Number ORNL/TM-2023/2885). Zenodo. https://doi.org/10.5281/zenodo.7750670
[BibTex]@techreport{wcs2022, author = {Ferreira da Silva, Rafael and Badia, Rosa M. and Bala, Venkat and Bard, Debbie and Bremer, Timo and Buckley, Ian and Caino-Lores, Silvina and Chard, Kyle and Goble, Carole and Jha, Shantenu and Katz, Daniel S. and Laney, Daniel and Parashar, Manish and Suter, Frederic and Tyler, Nick and Uram, Thomas and Altintas, Ilkay and Andersson, Stefan and Arndt, William and Aznar, Juan and Bader, Jonathan and Balis, Bartosz and Blanton, Chris and Braghetto, Kelly Rosa and Brodutch, Aharon and Brunk, Paul and Casanova, Henri and Cervera Lierta, Alba and Chigu, Justin and Coleman, Taina and Collier, Nick and Colonnelli, Iacopo and Coppens, Frederik and Crusoe, Michael and Cunningham, Will and de Paula Kinoshita, Bruno and Di Tommaso, Paolo and Doutriaux, Charles and Downton, Matthew and Elwasif, Wael and Enders, Bjoern and Erdmann, Chris and Fahringer, Thomas and Figueiredo, Ludmilla and Filgueira, Rosa and Foltin, Martin and Fouilloux, Anne and Gadelha, Luiz and Gallo, Andy and Garcia, Artur and Garijo, Daniel and Gerlach, Roman and Grant, Ryan and Grayson, Samuel and Grubel, Patricia and Gustafsson, Johan and Hayot, Valerie and Hernandez, Oscar and Hilbrich, Marcus and Justine, Annmary and Laflotte, Ian and Lehmann, Fabian and Luckow, Andre and Luettgau, Jakob and Maheshwari, Ketan and Matsuda, Motohiko and Medic, Doriana and Mendygral, Pete and Michalewicz, Marek and Nonaka, Jorji and Pawlik, Maciej and Pottier, Loic and Pouchard, Line and Putz, Mathias and Radha, Santosh Kumar and Ramakrishnan, Lavanya and Ristov, Sashko and Romano, Paul and Rosendo, Daniel and Ruefenacht, Martin and Rycerz, Katarzyna and Saurabh, Nishant and Savchenko, Volodymyr and Schulz, Martin and Simpson, Christine and Sirvent, Raul and Skluzacek, Tyler and Soiland-Reyes, Stian and Souza, Renan and Sukumar, Sreenivas Rangan and Sun, Ziheng and Sussman, Alan and Thain, Douglas and Titov, Mikhail and Tovar, Benjamin and Tripathy, Aalap and Turilli, Matteo and Tuznik, Bartosz and van Dam, Hubertus and Vivas, Aurelio and Ward, Logan and Widener, Patrick and Wilkinson, Sean R. and Zawalska, Justyna and Zulfiqar, Mahnoor}, title = {{Workflows Community Summit 2022: A Roadmap Revolution}}, month = mar, year = {2023}, publisher = {Zenodo}, number = {ORNL/TM-2023/2885}, doi = {10.5281/zenodo.7750670}, institution = {Oak Ridge National Laboratory} } -
Gesing, S., Ma, J., Neeman, H., Christopherson, L., Colbry, D., Dougherty, M., Griffioen, J., Tussy, S., Crall, A., Goodhue, J., Ferreira da Silva, R., Chard, K., Brazil, M., & Cheatham, T. (2023). Community of Communities: A Working Group Enhancing Interactions Between Organizations and Projects Supporting RC Professionals. Gateways 2023.
[BibTex]@inproceedings{gesing2023gateways, title = {Community of Communities: A Working Group Enhancing Interactions Between Organizations and Projects Supporting RC Professionals}, author = {Gesing, Sandra and Ma, Julie and Neeman, Henry and Christopherson, Laura and Colbry, Dirk and Dougherty, Maureen and Griffioen, James and Tussy, Susan and Crall, Alycia and Goodhue, John and Ferreira da Silva, Rafael and Chard, Kyle and Brazil, Marisa and Cheatham, Thomas}, booktitle = {Gateways 2023}, pages = {}, year = {2023}, doi = {} } -
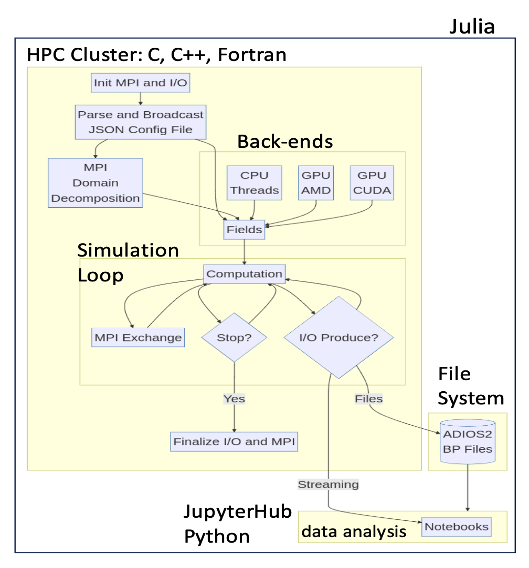
Godoy, W. F., Valero-Lara, P., Anderson, C., Lee, K. W., Gainaru, A., Ferreira da Silva, R., & Vetter, J. S. (2023). Julia as a unifying end-to-end workflow language on the Frontier exascale system. 2023 IEEE/ACM Workshop on Workflows in Support of Large-Scale Science (WORKS), 1989–1999. https://doi.org/10.1145/3624062.3624278
[BibTex]@inproceedings{godoy2023works, title = {Julia as a unifying end-to-end workflow language on the Frontier exascale system}, author = {Godoy, William F. and Valero-Lara, Pedro and Anderson, Caira and Lee, Katrina W. and Gainaru, Ana and Ferreira da Silva, Rafael and Vetter, Jeffrey S.}, booktitle = {2023 IEEE/ACM Workshop on Workflows in Support of Large-Scale Science (WORKS)}, pages = {1989--1999}, year = {2023}, doi = {10.1145/3624062.3624278} } -
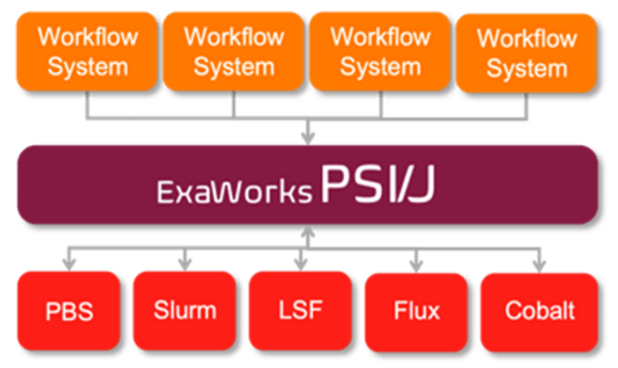
Hategan-Marandiuc, M., Merzky, A., Collier, N., Maheshwari, K., Ozik, J., Turilli, M., Wilke, A., Wozniak, J. M., Chard, K., Foster, I., Ferreira da Silva, R., Jha, S., & Laney, D. (2023). PSI/J: A Portable Interface for Submitting, Monitoring, and Managing Jobs. 19th IEEE Conference on EScience. https://doi.org/10.1109/e-Science58273.2023.10254912
[BibTex]@inproceedings{hategan2023escience, title = {PSI/J: A Portable Interface for Submitting, Monitoring, and Managing Jobs}, author = {Hategan-Marandiuc, Mihael and Merzky, Andre and Collier, Nicholson and Maheshwari, Ketan and Ozik, Jonathan and Turilli, Matteo and Wilke, Andreas and Wozniak, Justin M. and Chard, Kyle and Foster, Ian and Ferreira da Silva, Rafael and Jha, Shantenu and Laney, Daniel}, booktitle = {19th IEEE Conference on eScience}, pages = {}, year = {2023}, doi = {10.1109/e-Science58273.2023.10254912} } -
Souza, R., Skluzacek, T. J., Wilkinson, S. R., Ziatdinov, M., & Ferreira da Silva, R. (2023). Towards Lightweight Data Integration using Multi-workflow Provenance and Data Observability. 19th IEEE Conference on EScience. https://doi.org/10.1109/e-Science58273.2023.10254822
[BibTex]@inproceedings{souza2023escience, title = {Towards Lightweight Data Integration using Multi-workflow Provenance and Data Observability}, author = {Souza, Renan and Skluzacek, Tyler J. and Wilkinson, Sean R. and Ziatdinov, Maxim and Ferreira da Silva, Rafael}, booktitle = {19th IEEE Conference on eScience}, pages = {}, year = {2023}, doi = {10.1109/e-Science58273.2023.10254822} } -
Suter, F., Ferreira da Silva, R., Gainaru, A., & Klasky, S. (2023). Driving Next-Generation Workflows from the Data Plane. 19th IEEE Conference on EScience. https://doi.org/10.1109/e-Science58273.2023.10254849
[BibTex]@inproceedings{suter2023escience, title = {Driving Next-Generation Workflows from the Data Plane}, author = {Suter, Frederic and Ferreira da Silva, Rafael and Gainaru, Ana and Klasky, Scott}, booktitle = {19th IEEE Conference on eScience}, pages = {}, year = {2023}, doi = {10.1109/e-Science58273.2023.10254849} }
2022
-
Abhinit, I., Adams, E. K., Alam, K., Chase, B., Deelman, E., Gorenstein, L., Hudson, S., Islam, T., Larson, J., Lentner, G., Mandal, A., Navarro, J.-L., Nicolae, B., Pouchard, L., Ross, R., Roy, B., Rynge, M., Serebrenik, A., Vahi, K., … Filgueira, R. (2022). Novel Proposals for FAIR, Automated, Recommendable, and Robust Workflows. 2022 IEEE/ACM Workshop on Workflows in Support of Large-Scale Science (WORKS), 84–92. https://doi.org/10.1109/WORKS56498.2022.00016
[BibTex]@inproceedings{adams2022works, author = {Abhinit, Ishan and Adams, Emily K. and Alam, Khairul and Chase, Brian and Deelman, Ewa and Gorenstein, Lev and Hudson, Stephen and Islam, Tanzima and Larson, Jeffrey and Lentner, Geoffrey and Mandal, Anirban and Navarro, John-Luke and Nicolae, Bogdan and Pouchard, Line and Ross, Rob and Roy, Banani and Rynge, Mats and Serebrenik, Alexander and Vahi, Karan and Wild, Stefan and Xin, Yufeng and Ferreira da Silva, Rafael and Filgueira, Rosa}, title = {Novel Proposals for FAIR, Automated, Recommendable, and Robust Workflows}, booktitle = {2022 IEEE/ACM Workshop on Workflows in Support of Large-Scale Science (WORKS)}, pages = {84--92}, year = {2022}, doi = {10.1109/WORKS56498.2022.00016} } -
Bücker, H. M., Casanova, H., Ferreira da Silva, R., Lasserre, A., Luyen, D., Namyst, R., Schoder, J., Wacrenier, P.-A., & Bunde, D. P. (2022). Peachy Parallel Assignments (EduPar 2022). 12th NSF/TCPP Workshop on Parallel and Distributed Computing Education (EduPar), 361–368. https://doi.org/10.1109/IPDPSW55747.2022.00068
[BibTex]@inproceedings{bucker2022edupar, title = {Peachy Parallel Assignments (EduPar 2022)}, author = {Bücker, H. Martin and Casanova, Henri and Ferreira da Silva, Rafael and Lasserre, Alice and Luyen, Derrick and Namyst, Raymond and Schoder, Johannes and Wacrenier, Pierre-Andre and Bunde, David P.}, booktitle = {12th NSF/TCPP Workshop on Parallel and Distributed Computing Education (EduPar)}, pages = {361--368}, year = {2022}, doi = {10.1109/IPDPSW55747.2022.00068} } -
Coleman, T., Casanova, H., Pottier, L., Kaushik, M., Deelman, E., & Ferreira da Silva, R. (2022). WfCommons: A Framework for Enabling Scientific Workflow Research and Development. Future Generation Computer Systems, 128, 16–27. https://doi.org/10.1016/j.future.2021.09.043
[BibTex]@article{coleman2021fgcs, title = {WfCommons: A Framework for Enabling Scientific Workflow Research and Development}, author = {Coleman, Tain\~a and Casanova, Henri and Pottier, Lo\"ic and Kaushik, Manav and Deelman, Ewa and Ferreira da Silva, Rafael}, journal = {Future Generation Computer Systems}, volume = {128}, number = {}, pages = {16--27}, doi = {10.1016/j.future.2021.09.043}, year = {2022} } -
Coleman, T., Cansanova, H., Maheshwari, K., Pottier, L., Wilkinson, S. R., Wozniak, J., Suter, F., Shankar, M., & Ferreira da Silva, R. (2022). WfBench: Automated Generation of Scientific Workflow Benchmarks. 2022 IEEE/ACM International Workshop on Performance Modeling, Benchmarking and Simulation of High Performance Computer Systems (PMBS), 100–111. https://doi.org/10.1109/PMBS56514.2022.00014
[BibTex]@inproceedings{coleman2022pmbs, author = {Coleman, Taina and Cansanova, Henri and Maheshwari, Ketan and Pottier, Loïc and Wilkinson, Sean R. and Wozniak, Justin and Suter, Frédéric and Shankar, Mallikarjun and Ferreira da Silva, Rafael}, title = {{WfBench: Automated Generation of Scientific Workflow Benchmarks}}, booktitle = {2022 IEEE/ACM International Workshop on Performance Modeling, Benchmarking and Simulation of High Performance Computer Systems (PMBS)}, pages = {100--111}, year = {2022}, doi = {10.1109/PMBS56514.2022.00014} } -
Do, T. M. A., Pottier, L., Ferreira da Silva, R., Caíno-Lores, S., Taufer, M., & Deelman, E. (2022). Performance assessment of ensembles of in situ workflows under resource constraints. Concurrency and Computation: Practice and Experience. https://doi.org/10.1002/cpe.7111
[BibTex]@article{do2022cpe, author = {Do, Tu Mai Anh and Pottier, Loïc and Ferreira da Silva, Rafael and Caíno-Lores, Silvina and Taufer, Michela and Deelman, Ewa}, title = {Performance assessment of ensembles of in situ workflows under resource constraints}, journal = {Concurrency and Computation: Practice and Experience}, volume = {}, number = {}, pages = {}, year = {2022}, doi = {10.1002/cpe.7111} } -
Do, T. M. A., Pottier, L., Ferreira da Silva, R., Suter, F., Caíno-Lores, S., Taufer, M., & Deelman, E. (2022). Co-scheduling Ensembles of In Situ Workflows. 2022 IEEE/ACM Workshop on Workflows in Support of Large-Scale Science (WORKS), 43–51. https://doi.org/10.1109/WORKS56498.2022.00011
[BibTex]@inproceedings{do2022works, author = {Do, Tu Mai Anh and Pottier, Loïc and Ferreira da Silva, Rafael and Suter, Frédéric and Caíno-Lores, Silvina and Taufer, Michela and Deelman, Ewa}, title = {Co-scheduling Ensembles of In Situ Workflows}, booktitle = {2022 IEEE/ACM Workshop on Workflows in Support of Large-Scale Science (WORKS)}, pages = {43--51}, year = {2022}, doi = {10.1109/WORKS56498.2022.00011} } -
Ferreira da Silva, R., Chard, K., Casanova, H., Laney, D., Ahn, D., Jha, S., Allcock, W. E., Bauer, G., Duplyakin, D., Enders, B., Heer, T. M., Lançon, E., Sanielevici, S., & Sayers, K. (2022). Workflows Community Summit: Tightening the Integration between Computing Facilities and Scientific Workflows. Zenodo. https://doi.org/10.5281/zenodo.5815332
[BibTex]@misc{wcs2021facilities, author = {Ferreira da Silva, Rafael and Chard, Kyle and Casanova, Henri and Laney, Dan and Ahn, Dong and Jha, Shantenu and Allcock, William E. and Bauer, Gregory and Duplyakin, Dmitry and Enders, Bjoern and Heer, Todd M. and Lan\c{c}on, Eric and Sanielevici, Sergiu and Sayers, Kevin}, title = {{Workflows Community Summit: Tightening the Integration between Computing Facilities and Scientific Workflows}}, month = jan, year = {2022}, publisher = {Zenodo}, doi = {10.5281/zenodo.5815332} } -
Honore, V., Do, T. M. A., Pottier, L., Ferreira da Silva, R., Deelman, E., & Suter, F. (2022). Sim-Situ: A Framework for the Faithful Simulation of in situ Processing. 2022 IEEE 18th International Conference on EScience (EScience), 182–191. https://doi.org/10.1109/eScience55777.2022.00032
[BibTex]@inproceedings{honore2022escience, author = {Honore, Valentin and Do, Tu Mai Anh and Pottier, Loic and Ferreira da Silva, Rafael and Deelman, Ewa and Suter, Frederic}, title = {Sim-Situ: A Framework for the Faithful Simulation of in situ Processing}, booktitle = {2022 IEEE 18th International Conference on eScience (eScience)}, pages = {182--191}, year = {2022}, doi = {10.1109/eScience55777.2022.00032} } -
Maheshwari, K., Wilkinson, S. R., May, A., Skluzacek, T., Kuchar, O. A., & Ferreira da Silva, R. (2022). Pseudonymization at Scale: OLCF’s Summit Usage Data Case Study. 2022 IEEE International Conference on Big Data (Big Data).
[BibTex]@inproceedings{maheshwari2022btsd, author = {Maheshwari, Ketan and Wilkinson, Sean R. and May, Alex and Skluzacek, Tyler and Kuchar, Olga A. and Ferreira da Silva, Rafael}, title = {Pseudonymization at Scale: OLCF's Summit Usage Data Case Study}, booktitle = {2022 IEEE International Conference on Big Data (Big Data)}, pages = {}, year = {2022}, doi = {} } -
Wilkinson, S., Maheshwari, K., & Ferreira da Silva, R. (2022). Unveiling User Behavior on Summit Login Nodes as a User. Computational Science – ICCS 2022, 516–529. https://doi.org/10.1007/978-3-031-08751-6_37
[BibTex]@inproceedings{wilkinson2022iccs, title = {Unveiling User Behavior on Summit Login Nodes as a User}, author = {Wilkinson, Sean and Maheshwari, Ketan and Ferreira da Silva, Rafael}, booktitle = {Computational Science -- ICCS 2022}, pages = {516--529}, year = {2022}, doi = {10.1007/978-3-031-08751-6_37} }
2021
-
Brown, A. W., Aslibekyan, S., Bier, D., Ferreira da Silva, R., Hoover, A., Klurfeld, D. M., Loken, E., Mayo-Wilson, E., Menachemi, N., Pavela, G., D., P., Quinn, Schoeller, D., Carmen, Tekwe, Danny, Valdez, Vorland, C. J., Whigham, L. D., & Allison, D. B. (2021). Toward more rigorous and informative nutritional epidemiology: The rational space between dismissal and defense of the status quo. Critical Reviews in Food Science and Nutrition, 0(0), 1–18. https://doi.org/10.1080/10408398.2021.1985427
[BibTex]@article{brown2021toward, author = {Brown, Andrew W. and Aslibekyan, Stella and Bier, Dennis and Ferreira da Silva, Rafael and Hoover, Adam and Klurfeld, David M. and Loken, Eric and Mayo-Wilson, Evan and Menachemi, Nir and Pavela, Greg and D., Patrick and Quinn and Schoeller, Dale and Carmen and Tekwe and Danny and Valdez and Vorland, Colby J. and Whigham, Leah D. and Allison, David B.}, title = {Toward more rigorous and informative nutritional epidemiology: The rational space between dismissal and defense of the status quo}, journal = {Critical Reviews in Food Science and Nutrition}, volume = {0}, number = {0}, pages = {1-18}, year = {2021}, publisher = {Taylor & Francis}, doi = {10.1080/10408398.2021.1985427} } -
Burkat, K., Pawlik, M., Balis, B., Malawski, M., Vahi, K., Rynge, M., Ferreira da Silva, R., & Deelman, E. (2021). Serverless Containers – Rising Viable Approach to Scientific Workflows. 17th IEEE EScience Conference, 40–49. https://doi.org/10.1109/eScience51609.2021.00014
[BibTex]@inproceedings{coleman2021esciencf, author = {Burkat, Krzysztof and Pawlik, Maciej and Balis, Bartosz and Malawski, Maciej and Vahi, Karan and Rynge, Mats and Ferreira da Silva, Rafael and Deelman, Ewa}, title = {Serverless Containers -- Rising Viable Approach to Scientific Workflows}, booktitle = {17th IEEE eScience Conference}, year = {2021}, pages = {40--49}, doi = {10.1109/eScience51609.2021.00014} } -
Casanova, H., Deelman, E., Gesing, S., Hildreth, M., Hudson, S., Koch, W., Larson, J., McDowell, M. A., Meyers, N., Navarro, J.-L., Papadimitriou, G., Tanaka, R., Taylor, I., Thain, D., Wild, S. M., Filgueira, R., & Ferreira da Silva, R. (2021). Emerging Frameworks for Advancing Scientific Workflows Research, Development, and Education. 2021 IEEE Workshop on Workflows in Support of Large-Scale Science (WORKS), 74–80. https://doi.org/10.1109/WORKS54523.2021.00015
[BibTex]@inproceedings{casanova2021works, title = {Emerging Frameworks for Advancing Scientific Workflows Research, Development, and Education}, author = {Casanova, Henri and Deelman, Ewa and Gesing, Sandra and Hildreth, Michael and Hudson, Stephen and Koch, William and Larson, Jeffrey and McDowell, Mary Ann and Meyers, Natalie and Navarro, John-Luke and Papadimitriou, George and Tanaka, Ryan and Taylor, Ian and Thain, Douglas and Wild, Stefan M. and Filgueira, Rosa and Ferreira da Silva, Rafael}, booktitle = {2021 IEEE Workshop on Workflows in Support of Large-Scale Science (WORKS)}, pages = {74--80}, year = {2021}, doi = {10.1109/WORKS54523.2021.00015} } -
Casanova, H., Ferreira da Silva, R., Gonzalez-Escribano, A., Li, H., Torres, Y., & Bunde, D. P. (2021). Peachy Parallel Assignments (EduHPC 2021). 2021 IEEE/ACM Ninth Workshop on Education for High Performance Computing (EduHPC), 51–57. https://doi.org/10.1109/EduHPC54835.2021.00012
[BibTex]@inproceedings{casanova2021eduhpc, title = {Peachy Parallel Assignments (EduHPC 2021)}, author = {Casanova, Henri and Ferreira da Silva, Rafael and Gonzalez-Escribano, Arturo and Li, Herman and Torres, Yuri and Bunde, David P.}, booktitle = {2021 IEEE/ACM Ninth Workshop on Education for High Performance Computing (EduHPC)}, pages = {51--57}, year = {2021}, doi = {10.1109/EduHPC54835.2021.00012} } -
Casanova, H., Tanaka, R., Koch, W., & Ferreira da Silva, R. (2021). Teaching Parallel and Distributed Computing Concepts in Simulation with WRENCH. Journal of Parallel and Distributed Computing, 156, 53–63. https://doi.org/10.1016/j.jpdc.2021.05.009
[BibTex]@article{casanova2021jpdc, title = {Teaching Parallel and Distributed Computing Concepts in Simulation with WRENCH}, author = {Casanova, Henri and Tanaka, Ryan and Koch, William and Ferreira da Silva, Rafael}, journal = {Journal of Parallel and Distributed Computing}, volume = {156}, number = {}, pages = {53--63}, doi = {10.1016/j.jpdc.2021.05.009}, year = {2021} } -
Coleman, T., Casanova, H., Gwartney, T., & Ferreira da Silva, R. (2021). Evaluating energy-aware scheduling algorithms for I/O-intensive scientific workflows. International Conference on Computational Science (ICCS), 183–197. https://doi.org/10.1007/978-3-030-77961-0_16
[BibTex]@inproceedings{coleman2021iccs, author = {Coleman, Tain\~a and Casanova, Henri and Gwartney, Ty and Ferreira da Silva, Rafael}, title = {Evaluating energy-aware scheduling algorithms for I/O-intensive scientific workflows}, booktitle = {International Conference on Computational Science (ICCS)}, year = {2021}, pages = {183--197}, doi = {10.1007/978-3-030-77961-0_16}, organization = {Springer} } -
Coleman, T., Casanova, H., & Ferreira da Silva, R. (2021). WfChef: Automated Generation of Accurate Scientific Workflow Generators. 17th IEEE EScience Conference, 159–168. https://doi.org/10.1109/eScience51609.2021.00026
[BibTex]@inproceedings{coleman2021escience, author = {Coleman, Taina and Casanova, Henri and Ferreira da Silva, Rafael}, title = {WfChef: Automated Generation of Accurate Scientific Workflow Generators}, booktitle = {17th IEEE eScience Conference}, year = {2021}, pages = {159--168}, doi = {10.1109/eScience51609.2021.00026} } -
Deelman, E., Ferreira da Silva, R., Vahi, K., Rynge, M., Mayani, R., Tanaka, R., Whitcup, W., & Livny, M. (2021). The Pegasus Workflow Management System: Translational Computer Science in Practice. Journal of Computational Science, 52, 101200. https://doi.org/10.1016/j.jocs.2020.101200
[BibTex]@article{deelman2021jocs, title = {The Pegasus Workflow Management System: Translational Computer Science in Practice}, author = {Deelman, Ewa and Ferreira da Silva, Rafael and Vahi, Karan and Rynge, Mats and Mayani, Rajiv and Tanaka, Ryan and Whitcup, Wendy and Livny, Miron}, journal = {Journal of Computational Science}, volume = {52}, number = {}, pages = {101200}, year = {2021}, doi = {10.1016/j.jocs.2020.101200} } -
Deelman, E., Mandal, A., Murillo, A. P., Nabrzyski, J., Pascucci, V., Ricci, R., Baldin, I., Sons, S., Christopherson, L., Vardeman, C., Ferreira da Silva, R., Wyngaard, J., Petruzza, S., Rynge, M., Vahi, K., Whitcup, W. R., Drake, J., & Scott, E. (2021). Blueprint: Cyberinfrastructure Center of Excellence. Zenodo. https://doi.org/10.5281/zenodo.4587866
[BibTex]@article{deelman2021blueprint, title = {{Blueprint: Cyberinfrastructure Center of Excellence}}, author = {Deelman, Ewa and Mandal, Anirban and Murillo, Angela P. and Nabrzyski, Jarek and Pascucci, Valerio and Ricci, Robert and Baldin, Ilya and Sons, Susan and Christopherson, Laura and Vardeman, Charles and Ferreira da Silva, Rafael and Wyngaard, Jane and Petruzza, Steve and Rynge, Mats and Vahi, Karan and Whitcup, Wendy R. and Drake, Josh and Scott, Erik}, journal = {Zenodo}, year = {2021}, doi = {10.5281/zenodo.4587866} } -
Do, H.-D., Hayot-Sasson, V., Ferreira da Silva, R., Steele, C., Casanova, H., & Glatard, T. (2021). Modeling the Linux page cache for accurate simulation of data-intensive applications. 2021 IEEE International Conference on Cluster Computing (CLUSTER), 398–408. https://doi.org/10.1109/Cluster48925.2021.00058
[BibTex]@inproceedings{do2021cluster, author = {Do, Hoang-Dung and Hayot-Sasson, Val\'erie and Ferreira da Silva, Rafael and Steele, Christopher and Casanova, Henri and Glatard, Tristan}, title = {Modeling the Linux page cache for accurate simulation of data-intensive applications}, booktitle = {2021 IEEE International Conference on Cluster Computing (CLUSTER)}, year = {2021}, pages = {398--408}, doi = {10.1109/Cluster48925.2021.00058} } -
Do, T. M. A., Pottier, L., Caíno-Lores, S., Ferreira da Silva, R., Cuendet, M. A., Weinstein, H., Estrada, T., Taufer, M., & Deelman, E. (2021). A Lightweight Method for Evaluating In Situ Workflow Efficiency. Journal of Computational Science, 48, 101259. https://doi.org/10.1016/j.jocs.2020.101259
[BibTex]@article{do2020jocs, title = {A Lightweight Method for Evaluating In Situ Workflow Efficiency}, author = {Do, Tu Mai Anh and Pottier, Lo\"ic and Ca\'ino-Lores, Silvina and Ferreira da Silva, Rafael and Cuendet, Michel A. and Weinstein, Harel and Estrada, Trilce and Taufer, Michela and Deelman, Ewa}, journal = {Journal of Computational Science}, volume = {48}, number = {}, pages = {101259}, year = {2021}, doi = {10.1016/j.jocs.2020.101259} } -
Do, T. M. A., Pottier, L., Ferreira da Silva, R., Caíno-Lores, S., Taufer, M., & Deelman, E. (2021). Assessing Resource Provisioning and Allocation of Ensembles of In Situ Workflows. 14th International Workshop on Parallel Programming Models and Systems Software for High-End Computing (P2S2), 1–10. https://doi.org/10.1145/3458744.3474051
[BibTex]@inproceedings{do2021p2s2, author = {Do, Tu Mai Anh and Pottier, Lo\"ic and Ferreira da Silva, Rafael and Ca\'ino-Lores, Silvina and Taufer, Michela and Deelman, Ewa}, title = {Assessing Resource Provisioning and Allocation of Ensembles of In Situ Workflows}, booktitle = {14th International Workshop on Parallel Programming Models and Systems Software for High-End Computing (P2S2)}, year = {2021}, pages = {1--10}, doi = {10.1145/3458744.3474051} } -
Ferreira da Silva, R., Casanova, H., Chard, K., Altintas, I., Badia, R. M., Balis, B., Coleman, T., Coppens, F., Di Natale, F., Enders, B., Fahringer, T., Filgueira, R., Fursin, G., Garijo, D., Goble, C., Howell, D., Jha, S., Katz, D. S., Laney, D., … Wolf, M. (2021). A Community Roadmap for Scientific Workflows Research and Development. 2021 IEEE Workshop on Workflows in Support of Large-Scale Science (WORKS), 81–90. https://doi.org/10.1109/WORKS54523.2021.00016
[BibTex]@inproceedings{ferreiradasilva2021works, title = {A Community Roadmap for Scientific Workflows Research and Development}, author = {Ferreira da Silva, Rafael and Casanova, Henri and Chard, Kyle and Altintas, Ilkay and Badia, Rosa M and Balis, Bartosz and Coleman, Tain\~a and Coppens, Frederik and Di Natale, Frank and Enders, Bjoern and Fahringer, Thomas and Filgueira, Rosa and Fursin, Grigori and Garijo, Daniel and Goble, Carole and Howell, Dorran and Jha, Shantenu and Katz, Daniel S. and Laney, Daniel and Leser, Ulf and Malawski, Maciej and Mehta, Kshitij and Pottier, Lo\"ic and Ozik, Jonathan and Peterson, J. Luc and Ramakrishnan, Lavanya and Soiland-Reyes, Stian and Thain, Douglas and Wolf, Matthew}, booktitle = {2021 IEEE Workshop on Workflows in Support of Large-Scale Science (WORKS)}, pages = {81--90}, year = {2021}, doi = {10.1109/WORKS54523.2021.00016} } -
Ferreira da Silva, R., Casanova, H., Chard, K., Coleman, T., Laney, D., Ahn, D., Jha, S., Howell, D., Soiland-Reys, S., Altintas, I., Thain, D., Filgueira, R., Babuji, Y., Badia, R. M., Balis, B., Caino-Lores, S., Callaghan, S., Coppens, F., Crusoe, M. R., … Wozniak, J. (2021). Workflows Community Summit: Advancing the State-of-the-art of Scientific Workflows Management Systems Research and Development. Zenodo. https://doi.org/10.5281/zenodo.4915801
[BibTex]@misc{wcs2021technical, author = {Ferreira da Silva, Rafael and Casanova, Henri and Chard, Kyle and Coleman, Tain\~a and Laney, Dan and Ahn, Dong and Jha, Shantenu and Howell, Dorran and Soiland-Reys, Stian and Altintas, Ilkay and Thain, Douglas and Filgueira, Rosa and Babuji, Yadu and Badia, Rosa M. and Balis, Bartosz and Caino-Lores, Silvina and Callaghan, Scott and Coppens, Frederik and Crusoe, Michael R. and De, Kaushik and Di Natale, Frank and Do, Tu M. A. and Enders, Bjoern and Fahringer, Thomas and Fouilloux, Anne and Fursin, Grigori and Gaignard, Alban and Ganose, Alex and Garijo, Daniel and Gesing, Sandra and Goble, Carole and Hasan, Adil and Huber, Sebastiaan and Katz, Daniel S. and Leser, Ulf and Lowe, Douglas and Ludaescher, Bertram and Maheshwari, Ketan and Malawski, Maciej and Mayani, Rajiv and Mehta, Kshitij and Merzky, Andre and Munson, Todd and Ozik, Jonathan and Pottier, Lo\"{i}c and Ristov, Sashko and Roozmeh, Mehdi and Souza, Renan and Suter, Fr\'ed\'eric and Tovar, Benjamin and Turilli, Matteo and Vahi, Karan and Vidal-Torreira, Alvaro and Whitcup, Wendy and Wilde, Michael and Williams, Alan and Wolf, Matthew and Wozniak, Justin}, title = {{Workflows Community Summit: Advancing the State-of-the-art of Scientific Workflows Management Systems Research and Development}}, month = jun, year = {2021}, publisher = {Zenodo}, doi = {10.5281/zenodo.4915801} } -
Ferreira da Silva, R., Casanova, H., Chard, K., Laney, D., Ahn, D., Jha, S., Goble, C., Ramakrishnan, L., Peterson, L., Enders, B., Thain, D., Altintas, I., Babuji, Y., Badia, R., Bonazzi, V., Coleman, T., Crusoe, M., Deelman, E., Di Natale, F., … Wozniak, J. (2021). Workflows Community Summit: Bringing the Scientific Workflows Community Together. Zenodo. https://doi.org/10.5281/zenodo.4606958
[BibTex]@misc{ferreiradasilva2021wcs, author = {Ferreira da Silva, Rafael and Casanova, Henri and Chard, Kyle and Laney, Dan and Ahn, Dong and Jha, Shantenu and Goble, Carole and Ramakrishnan, Lavanya and Peterson, Luc and Enders, Bjoern and Thain, Douglas and Altintas, Ilkay and Babuji, Yadu and Badia, Rosa and Bonazzi, Vivien and Coleman, Taina and Crusoe, Michael and Deelman, Ewa and Di Natale, Frank and Di Tommaso, Paolo and Fahringer, Thomas and Filgueira, Rosa and Fursin, Grigori and Ganose, Alex and Gruning, Bjorn and Katz, Daniel S. and Kuchar, Olga and Kupresanin, Ana and Ludascher, Bertram and Maheshwari, Ketan and Mattoso, Marta and Mehta, Kshitij and Munson, Todd and Ozik, Jonathan and Peterka, Tom and Pottier, Loic and Randles, Tim and Soiland-Reyes, Stian and Tovar, Benjamin and Turilli, Matteo and Uram, Thomas and Vahi, Karan and Wilde, Michael and Wolf, Matthew and Wozniak, Justin}, title = {{Workflows Community Summit: Bringing the Scientific Workflows Community Together}}, month = mar, year = {2021}, publisher = {Zenodo}, doi = {10.5281/zenodo.4606958} } -
Gil, Y., Garijo, D., Khider, D., Knoblock, C. A., Ratnakar, V., Osorio, M., Vargas, H., Pham, M., Pujara, J., Shbita, B., Vu, B., Chiang, Y.-Y., Feldman, D., Lin, Y., Song, H., Kumar, V., Khandelwal, A., Steinbach, M., Tayal, K., … Shu, L. (2021). Artificial Intelligence for Modeling Complex Systems: Taming the Complexity of Expert Models to Improve Decision Making. ACM Transactions on Interactive Intelligent Systems, 11(2), 1–49. https://doi.org/10.1145/3453172
[BibTex]@article{gil2021tiis, title = {Artificial Intelligence for Modeling Complex Systems: Taming the Complexity of Expert Models to Improve Decision Making}, author = {Gil, Yolanda and Garijo, Daniel and Khider, Deborah and Knoblock, Craig A. and Ratnakar, Varun and Osorio, Maximiliano and Vargas, Hernán and Pham, Minh and Pujara, Jay and Shbita, Basel and Vu, Binh and Chiang, Yao-Yi and Feldman, Dan and Lin, Yijun and Song, Hayley and Kumar, Vipin and Khandelwal, Ankush and Steinbach, Michael and Tayal, Kshitij and Xu, Shaoming and Pierce, Suzanne A. and Pearson, Lissa and Hardesty-Lewis, Daniel and Deelman, Ewa and Ferreira da Silva, Rafael and Mayani, Rajiv and Kemanian, Armen R. and Shi, Yuning and Leonard, Lorne and Peckham, Scott and Stoica, Maria and Cobourn, Kelly and Zhang, Zeya and Duffy, Christopher and Shu, Lele}, journal = {ACM Transactions on Interactive Intelligent Systems}, volume = {11}, number = {2}, pages = {1--49}, doi = {10.1145/3453172}, year = {2021} } -
Hataishi, E., Dutot, P.-F., Ferreira da Silva, R., & Casanova, H. (2021). GLUME: A Strategy for Reducing Workflow Execution Times on Batch-Scheduled Platforms. Workshop on Job Scheduling Strategies for Parallel Processing (JSSPP), 210–230. https://doi.org/10.1007/978-3-030-88224-2_11
[BibTex]@inproceedings{hataishi2021jsspp, author = {Hataishi, Evan and Dutot, Pierre-Francois and Ferreira da Silva, Rafael and Casanova, Henri}, title = {GLUME: A Strategy for Reducing Workflow Execution Times on Batch-Scheduled Platforms}, booktitle = {Workshop on Job Scheduling Strategies for Parallel Processing (JSSPP)}, year = {2021}, pages = {210--230}, doi = {10.1007/978-3-030-88224-2_11} } -
Papadimitriou, G., Wang, C., Vahi, K., Ferreira da Silva, R., Mandal, A., Zhengchun, L., Mayani, R., Rynge, M., Kiran, M., Lynch, V. E., Kettimuthu, R., Deelman, E., Vetter, J. S., & Foster, I. (2021). End-to-End Online Performance Data Capture and Analysis for Scientific Workflows. Future Generation Computer Systems, 117, 387–400. https://doi.org/10.1016/j.future.2020.11.024
[BibTex]@article{papadimitriou2020fgcs, title = {End-to-End Online Performance Data Capture and Analysis for Scientific Workflows}, author = {Papadimitriou, George and Wang, Cong and Vahi, Karan and Ferreira da Silva, Rafael and Mandal, Anirban and Zhengchun, Liu and Mayani, Rajiv and Rynge, Mats and Kiran, Mariam and Lynch, Vickie E. and Kettimuthu, Rajkumar and Deelman, Ewa and Vetter, Jeffrey S. and Foster, Ian}, journal = {Future Generation Computer Systems}, year = {2021}, volume = {117}, number = {}, pages = {387--400}, doi = {10.1016/j.future.2020.11.024} } -
Taufer, M., Deelman, E., da Silva, R. F., Estrada, T., & Hall, M. (2021). A Roadmap to Robust Science for High-throughput Applications: The Scientists’ Perspective. 2021 IEEE 17th International Conference on EScience (EScience), 247–248. https://doi.org/10.1109/eScience51609.2021.00044
[BibTex]@inproceedings{taufer2021escience, title = {A Roadmap to Robust Science for High-throughput Applications: The Scientists’ Perspective}, author = {Taufer, M and Deelman, E and da Silva, R Ferreira and Estrada, T and Hall, M}, booktitle = {2021 IEEE 17th International Conference on eScience (eScience)}, pages = {247--248}, year = {2021}, organization = {IEEE Computer Society}, doi = {10.1109/eScience51609.2021.00044} } -
Taufer, M., Deelman, E., Ferreira da Silva, R., Estrada, T., Hall, M., & Livny, M. (2021). A Roadmap to Robust Science for High-throughput Applications: The Developers’ Perspective. 2021 IEEE International Conference on Cluster Computing (CLUSTER), 807–808. https://doi.org/10.1109/Cluster48925.2021.00068
[BibTex]@inproceedings{taufer2021roadmap, title = {A Roadmap to Robust Science for High-throughput Applications: The Developers’ Perspective}, author = {Taufer, Michela and Deelman, Ewa and Ferreira da Silva, Rafael and Estrada, Trilce and Hall, Mary and Livny, Miron}, booktitle = {2021 IEEE International Conference on Cluster Computing (CLUSTER)}, pages = {807--808}, year = {2021}, organization = {IEEE}, doi = {10.1109/Cluster48925.2021.00068} }
2020
-
Adams, J. C., Back, G., Bala, P., Bane, M. K., Cameron, K., Casanova, H., Ellis, M., Ferreira da Silva, R., Jethwani, G., Koch, W., Lee, T., & Zhu, T. (2020). Lightning Talks of EduHPC 2020. 2020 IEEE/ACM Workshop on Education for High-Performance Computing (EduHPC), 59–64. https://doi.org/10.1109/EduHPC51895.2020.00013
[BibTex]@inproceedings{adams2020eduhpc, author = {Adams, Joel C. and Back, Godmar and Bala, Piotr and Bane, Michael K. and Cameron, Kirk and Casanova, Henri and Ellis, Margaret and Ferreira da Silva, Rafael and Jethwani, Gautam and Koch, William and Lee, Tabitha and Zhu, Tongyu}, title = {Lightning Talks of EduHPC 2020}, booktitle = {2020 IEEE/ACM Workshop on Education for High-Performance Computing (EduHPC)}, pages = {59--64}, year = {2020}, doi = {10.1109/EduHPC51895.2020.00013} } -
Casanova, H., Ferreira da Silva, R., Gonzalez-Escribano, A., Koch, W., Torres, Y., & Bunde, D. P. (2020). Peachy Parallel Assignments (EduHPC 2020). 2020 IEEE/ACM Workshop on Education for High-Performance Computing (EduHPC), 53–58. https://doi.org/10.1109/EduHPC51895.2020.00012
[BibTex]@inproceedings{casanova2020eduhpc, title = {Peachy Parallel Assignments (EduHPC 2020)}, author = {Casanova, Henri and Ferreira da Silva, Rafael and Gonzalez-Escribano, Arturo and Koch, William and Torres, Yuri and Bunde, David P.}, booktitle = {2020 IEEE/ACM Workshop on Education for High-Performance Computing (EduHPC)}, pages = {53--58}, year = {2020}, doi = {10.1109/EduHPC51895.2020.00012} } -
Casanova, H., Ferreira da Silva, R., Tanaka, R., Pandey, S., Jethwani, G., Koch, W., Albrecht, S., Oeth, J., & Suter, F. (2020). Developing Accurate and Scalable Simulators of Production Workflow Management Systems with WRENCH. Future Generation Computer Systems, 112, 162–175. https://doi.org/10.1016/j.future.2020.05.030
[BibTex]@article{casanova2020fgcs, title = {Developing Accurate and Scalable Simulators of Production Workflow Management Systems with WRENCH}, author = {Casanova, Henri and Ferreira da Silva, Rafael and Tanaka, Ryan and Pandey, Suraj and Jethwani, Gautam and Koch, William and Albrecht, Spencer and Oeth, James and Suter, Fr\'{e}d\'{e}ric}, journal = {Future Generation Computer Systems}, volume = {112}, number = {}, pages = {162--175}, year = {2020}, doi = {10.1016/j.future.2020.05.030} } -
Do, T. M. A., Pottier, L., Thomas, S., Ferreira da Silva, R., Cuendet, M. A., Weinstein, H., Estrada, T., Taufer, M., & Deelman, E. (2020). A Novel Metric to Evaluate In Situ Workflows. International Conference on Computational Science (ICCS), 538–553. https://doi.org/10.1007/978-3-030-50371-0_40
[BibTex]@inproceedings{do2020iccs, author = {Do, Tu Mai Anh and Pottier, Loic and Thomas, Stephen and Ferreira da Silva, Rafael and Cuendet, Michel A. and Weinstein, Harel and Estrada, Trilce and Taufer, Michela and Deelman, Ewa}, title = {A Novel Metric to Evaluate In Situ Workflows}, booktitle = {International Conference on Computational Science (ICCS)}, year = {2020}, pages = {538--553}, doi = {10.1007/978-3-030-50371-0_40} } -
Ferreira da Silva, R., Casanova, H., Orgerie, A.-C., Tanaka, R., Deelman, E., & Suter, F. (2020). Characterizing, Modeling, and Accurately Simulating Power and Energy Consumption of I/O-intensive Scientific Workflows. Journal of Computational Science, 44, 101157. https://doi.org/10.1016/j.jocs.2020.101157
[BibTex]@article{ferreiradasilva2020jocs, title = {Characterizing, Modeling, and Accurately Simulating Power and Energy Consumption of I/O-intensive Scientific Workflows}, author = {Ferreira da Silva, Rafael and Casanova, Henri and Orgerie, Anne-C\'{e}cile and Tanaka, Ryan and Deelman, Ewa and Suter, Fr\'{e}d\'{e}ric}, journal = {Journal of Computational Science}, volume = {44}, number = {}, pages = {101157}, year = {2020}, doi = {10.1016/j.jocs.2020.101157} } -
Ferreira da Silva, R., Pottier, L., Coleman, T., Deelman, E., & Casanova, H. (2020). WorkflowHub: Community Framework for Enabling Scientific Workflow Research and Development. 2020 IEEE/ACM Workflows in Support of Large-Scale Science (WORKS), 49–56. https://doi.org/10.1109/WORKS51914.2020.00012
[BibTex]@inproceedings{ferreiradasilva2020works, title = {WorkflowHub: Community Framework for Enabling Scientific Workflow Research and Development}, author = {Ferreira da Silva, Rafael and Pottier, Lo\"ic and Coleman, Tain\~a and Deelman, Ewa and Casanova, Henri}, booktitle = {2020 IEEE/ACM Workflows in Support of Large-Scale Science (WORKS)}, year = {2020}, pages = {49--56}, doi = {10.1109/WORKS51914.2020.00012} } -
Pottier, L., Ferreira da Silva, R., Casanova, H., & Deelman, E. (2020). Modeling the Performance of Scientific Workflow Executions on HPC Platforms with Burst Buffers. 2020 IEEE International Conference on Cluster Computing (CLUSTER), 92–103. https://doi.org/10.1109/CLUSTER49012.2020.00019
[BibTex]@inproceedings{pottier2020cluster, author = {Pottier, Loic and Ferreira da Silva, Rafael and Casanova, Henri and Deelman, Ewa}, title = {Modeling the Performance of Scientific Workflow Executions on HPC Platforms with Burst Buffers}, booktitle = {2020 IEEE International Conference on Cluster Computing (CLUSTER)}, year = {2020}, pages = {92--103}, doi = {10.1109/CLUSTER49012.2020.00019} }
2019
-
Bogol, S., Brenner, P., Brinckman, A., Deelman, E., Ferreira da Silva, R., Gupta, S., Nabrzyski, J., Park, S., Perez, D., Rynge, M., Taylor, I., Vahi, K., Werf, M. V., Sarah, R., & Wyngaard, S. (2019). A Secure Gateway for Enabling ASIC Design Collaborations. 11th International Workshop on Science Gateways (IWSG 2019).
[BibTex]@inproceedings{bogol-iwsg-2019, title = {A Secure Gateway for Enabling ASIC Design Collaborations}, author = {Bogol, Steve and Brenner, Paul and Brinckman, Adam and Deelman, Ewa and Ferreira da Silva, Rafael and Gupta, Sandeep and Nabrzyski, Jarek and Park, Soowang and Perez, Damian and Rynge, Mats and Taylor, Ian and Vahi, Karan and Werf, Matt Vander and Sarah, Rucker and Wyngaard, Sebastian}, booktitle = {11th International Workshop on Science Gateways (IWSG 2019)}, year = {2019}, pages = {} } -
Brinckman, A., Deelman, E., Gupta, S., Nabrzyski, J., Park, S., Ferreira da Silva, R., Taylor, I. J., & Vahi, K. (2019). Collaborative Circuit Designs using the CRAFT Repository. Future Generation Computer Systems, 94, 841–853. https://doi.org/10.1016/j.future.2018.01.018
[BibTex]@article{brinckman-fgcs-2018, title = {Collaborative Circuit Designs using the CRAFT Repository}, author = {Brinckman, Adam and Deelman, Ewa and Gupta, Sandeep and Nabrzyski, Jarek and Park, Soowang and Ferreira da Silva, Rafael and Taylor, Ian J. and Vahi, Karan}, journal = {Future Generation Computer Systems}, volume = {94}, number = {}, pages = {841--853}, year = {2019}, doi = {10.1016/j.future.2018.01.018} } -
Deelman, E., Vahi, K., Rynge, M., Mayani, R., Ferreira da Silva, R., Papadimitriou, G., & Livny, M. (2019). The Evolution of the Pegasus Workflow Management Software. Computing in Science Engineering, 21(4), 22–36. https://doi.org/10.1109/MCSE.2019.2919690
[BibTex]@article{deelman-cise-2019, title = {The Evolution of the Pegasus Workflow Management Software}, author = {Deelman, Ewa and Vahi, Karan and Rynge, Mats and Mayani, Rajiv and Ferreira da Silva, Rafael and Papadimitriou, George and Livny, Miron}, journal = {Computing in Science Engineering}, volume = {21}, number = {4}, pages = {22--36}, year = {2019}, doi = {10.1109/MCSE.2019.2919690} } -
Ferreira da Silva, R., Callaghan, S., Do, T. M. A., Papadimitriou, G., & Deelman, E. (2019). Measuring the Impact of Burst Buffers on Data-Intensive Scientific Workflows. Future Generation Computer Systems, 101, 208–220. https://doi.org/10.1016/j.future.2019.06.016
[BibTex]@article{ferreiradasilva-fgcs-bb-2019, title = {Measuring the Impact of Burst Buffers on Data-Intensive Scientific Workflows}, author = {Ferreira da Silva, Rafael and Callaghan, Scott and Do, Tu Mai Anh and Papadimitriou, George and Deelman, Ewa}, journal = {Future Generation Computer Systems}, volume = {101}, number = {}, pages = {208--220}, year = {2019}, doi = {10.1016/j.future.2019.06.016} } -
Ferreira da Silva, R., Casanova, H., Tanaka, R., & Suter, F. (2019). Bridging Concepts and Practice in eScience via Simulation-driven Engineering. Workshop on Bridging from Concepts to Data and Computation for EScience (BC2DC’19), 15th International Conference on EScience (EScience), 609–614. https://doi.org/10.1109/eScience.2019.00084
[BibTex]@inproceedings{ferreiradasilva2019escience, title = {Bridging Concepts and Practice in eScience via Simulation-driven Engineering}, author = {Ferreira da Silva, Rafael and Casanova, Henri and Tanaka, Ryan and Suter, Frederic}, booktitle = {Workshop on Bridging from Concepts to Data and Computation for eScience (BC2DC'19), 15th International Conference on eScience (eScience)}, year = {2019}, pages = {609--614}, doi = {10.1109/eScience.2019.00084} } -
Ferreira da Silva, R., Filgueira, R., Deelman, E., Pairo-Castineira, E., Overton, I. M., & Atkinson, M. (2019). Using Simple PID-inspired Controllers for Online Resilient Resource Management of Distributed Scientific Workflows. Future Generation Computer Systems, 95, 615–628. https://doi.org/10.1016/j.future.2019.01.015
[BibTex]@article{ferreiradasilva-fgcs-2019, title = {Using Simple PID-inspired Controllers for Online Resilient Resource Management of Distributed Scientific Workflows}, author = {Ferreira da Silva, Rafael and Filgueira, Rosa and Deelman, Ewa and Pairo-Castineira, Erola and Overton, Ian Michael and Atkinson, Malcolm}, journal = {Future Generation Computer Systems}, volume = {95}, number = {}, pages = {615-628}, year = {2019}, doi = {10.1016/j.future.2019.01.015} } -
Ferreira da Silva, R., Mayani, R., Shi, Y., Kemanian, A. R., Rynge, M., & Deelman, E. (2019). Empowering Agroecosystem Modeling with HTC Scientific Workflows: The Cycles Model Use Case. 2019 IEEE International Conference on Big Data (Big Data), 4545–4552. https://doi.org/10.1109/BigData47090.2019.9006107
[BibTex]@inproceedings{ferreiradasilva2019btsd, title = {Empowering Agroecosystem Modeling with HTC Scientific Workflows: The Cycles Model Use Case}, author = {Ferreira da Silva, Rafael and Mayani, Rajiv and Shi, Yuning and Kemanian, Armen R. and Rynge, Mats and Deelman, Ewa}, booktitle = {2019 IEEE International Conference on Big Data (Big Data)}, year = {2019}, pages = {4545--4552}, doi = {10.1109/BigData47090.2019.9006107} } -
Ferreira da Silva, R., Orgerie, A.-C., Casanova, H., Tanaka, R., Deelman, E., & Suter, F. (2019). Accurately Simulating Energy Consumption of I/O-intensive Scientific Workflows. Computational Science – ICCS 2019, 138–152. https://doi.org/10.1007/978-3-030-22734-0_11
[BibTex]@inproceedings{ferreiradasilva-iccs-2019, author = {Ferreira da Silva, Rafael and Orgerie, Anne-C\'{e}cile and Casanova, Henri and Tanaka, Ryan and Deelman, Ewa and Suter, Fr\'{e}d\'{e}ric}, title = {Accurately Simulating Energy Consumption of I/O-intensive Scientific Workflows}, booktitle = {Computational Science -- ICCS 2019}, year = {2019}, pages = {138--152}, publisher = {Springer International Publishing}, doi = {10.1007/978-3-030-22734-0_11} } -
Garijo, D., Khider, D., Ratnakar, V., Gil, Y., Deelman, E., Ferreira da Silva, R., Knoblock, C., Chiang, Y.-Y., Pham, M., Pujara, J., Vu, B., Feldman, D., Mayani, R., Cobourn, K., Duffy, C., Kemanian, A., Shu, L., Kumar, V., Khandelwal, A., … Pierce, S. (2019). An Intelligent Interface for Integrating Climate, Hydrology, Agriculture, and Socioeconomic Models. ACM 24th International Conference on Intelligent User Interfaces (IUI’19), 111–112. https://doi.org/10.1145/3308557.3308711
[BibTex]@inproceedings{garijo-iui-2019, author = {Garijo, Daniel and Khider, Deborah and Ratnakar, Varun and Gil, Yolanda and Deelman, Ewa and Ferreira da Silva, Rafael and Knoblock, Craig and Chiang, Yao-Yi and Pham, Minh and Pujara, Jay and Vu, Binh and Feldman, Dan and Mayani, Rajiv and Cobourn, Kelly and Duffy, Chris and Kemanian, Armen and Shu, Lele and Kumar, Vipin and Khandelwal, Ankush and Tayal, Kshitij and Peckham, Scott and Stoica, Maria and Dabrowski, Anna and Hardesty-Lewis, Daniel and Pierce, Suzanne}, title = {An Intelligent Interface for Integrating Climate, Hydrology, Agriculture, and Socioeconomic Models}, booktitle = {ACM 24th International Conference on Intelligent User Interfaces (IUI'19)}, year = {2019}, pages = {111--112}, doi = {10.1145/3308557.3308711} } -
Herbein, S., Domyancic, D., Minner, P., Laguna, I., Ferreira da Silva, R., & Ahn, D. H. (2019). MCEM: Multi-Level Cooperative Exception Model for HPC Workflows. 9th International Workshop on Runtime and Operating Systems for Supercomputers (ROSS 2019). https://doi.org/10.1145/3322789.3328745
[BibTex]@inproceedings{herbein-ross-2019, author = {Herbein, Stephen and Domyancic, David and Minner, Paul and Laguna, Ignacio and Ferreira da Silva, Rafael and Ahn, Dong H.}, title = {MCEM: Multi-Level Cooperative Exception Model for HPC Workflows}, booktitle = {9th International Workshop on Runtime and Operating Systems for Supercomputers (ROSS 2019)}, year = {2019}, pages = {}, doi = {10.1145/3322789.3328745} } -
Mitchell, R., Pottier, L., Jacobs, S., Ferreira da Silva, R., Rynge, M., Vahi, K., & Deelman, E. (2019). Exploration of Workflow Management Systems Emerging Features from Users Perspectives. 2019 IEEE International Conference on Big Data (Big Data), 4537–4544. https://doi.org/10.1109/BigData47090.2019.9005494
[BibTex]@inproceedings{mitchell2019btsd, title = {Exploration of Workflow Management Systems Emerging Features from Users Perspectives}, author = {Mitchell, Ryan and Pottier, Loic and Jacobs, Steve and Ferreira da Silva, Rafael and Rynge, Mats and Vahi, Karan and Deelman, Ewa}, booktitle = {2019 IEEE International Conference on Big Data (Big Data)}, year = {2019}, pages = {4537--4544}, doi = {10.1109/BigData47090.2019.9005494} } -
Tanaka, R., Ferreira da Silva, R., & Casanova, H. (2019). Teaching Parallel and Distributed Computing Concepts in Simulation with WRENCH. Workshop on Education for High-Performance Computing (EduHPC). https://doi.org/10.1109/EduHPC49559.2019.00006
[BibTex]@inproceedings{tanaka2019eduhpc, title = {Teaching Parallel and Distributed Computing Concepts in Simulation with WRENCH}, author = {Tanaka, Ryan and Ferreira da Silva, Rafael and Casanova, Henri}, booktitle = {Workshop on Education for High-Performance Computing (EduHPC)}, year = {2019}, pages = {}, doi = {10.1109/EduHPC49559.2019.00006} } -
Thomas, S., Wyatt, M., Do, T. M. A., Pottier, L., Ferreira da Silva, R., Weinstein, H., Cuendet, M. A., Estrada, T., Deelman, E., & Taufer, M. (2019). Characterizing In Situ and In Transit Analytics of Molecular Dynamics Simulations for Next-generation Supercomputers. 15th International Conference on EScience (EScience), 188–198. https://doi.org/10.1109/eScience.2019.00027
[BibTex]@inproceedings{thomas-escience-2019, title = {Characterizing In Situ and In Transit Analytics of Molecular Dynamics Simulations for Next-generation Supercomputers}, author = {Thomas, Stephen and Wyatt, Michael and Do, Tu Mai Anh and Pottier, Loic and Ferreira da Silva, Rafael and Weinstein, Harel and Cuendet, Michel A. and Estrada, Trilce and Deelman, Ewa and Taufer, Michela}, booktitle = {15th International Conference on eScience (eScience)}, year = {2019}, pages = {188--198}, doi = {10.1109/eScience.2019.00027} } -
Vahi, K., Rynge, M., Papadimitriou, G., Brown, D., Mayani, R., Ferreira da Silva, R., Deelman, E., Mandal, A., Lyons, E., & Zink, M. (2019). Custom Execution Environments with Containers in Pegasus-enabled Scientific Workflows. 15th International Conference on EScience (EScience), 281–290. https://doi.org/10.1109/eScience.2019.00039
[BibTex]@inproceedings{vahi-escience-2019, title = {Custom Execution Environments with Containers in Pegasus-enabled Scientific Workflows}, author = {Vahi, Karan and Rynge, Mats and Papadimitriou, George and Brown, Duncan and Mayani, Rajiv and Ferreira da Silva, Rafael and Deelman, Ewa and Mandal, Anirban and Lyons, Eric and Zink, Michael}, booktitle = {15th International Conference on eScience (eScience)}, year = {2019}, pages = {281--290}, doi = {10.1109/eScience.2019.00039} }
2018
-
Casanova, H., Pandey, S., Oeth, J., Tanaka, R., Suter, F., & Ferreira da Silva, R. (2018). WRENCH: A Framework for Simulating Workflow Management Systems. 13th Workshop on Workflows in Support of Large-Scale Science (WORKS’18), 74–85. https://doi.org/10.1109/WORKS.2018.00013
[BibTex]@inproceedings{casanova-works-2018, title = {WRENCH: A Framework for Simulating Workflow Management Systems}, author = {Casanova, Henri and Pandey, Suraj and Oeth, James and Tanaka, Ryan and Suter, Frederic and Ferreira da Silva, Rafael}, booktitle = {13th Workshop on Workflows in Support of Large-Scale Science (WORKS'18)}, year = {2018}, pages = {74--85}, doi = {10.1109/WORKS.2018.00013} } -
Ferreira da Silva, R., Garijo, D., Peckham, S., Gil, Y., Deelman, E., & Ratnakar, V. (2018). Towards Model Integration via Abductive Workflow Composition and Multi-Method Scalable Model Execution. 9th International Congress on Environmental Modelling and Software.
[BibTex]@inproceedings{ferreiradasilva-iemss-2018, title = {Towards Model Integration via Abductive Workflow Composition and Multi-Method Scalable Model Execution}, author = {Ferreira da Silva, Rafael and Garijo, Daniel and Peckham, Scott and Gil, Yolanda and Deelman, Ewa and Ratnakar, Varun}, booktitle = {9th International Congress on Environmental Modelling and Software}, year = {2018}, pages = {}, doi = {} } -
Filgueira, R., Ferreira da Silva, R., Deelman, E., Christodoulou, V., & Krause, A. (2018). IoT-Hub: New IoT data-platform for Virtual Research Environments. 10th International Workshop on Science Gateways (IWSG 2018).
[BibTex]@inproceedings{filgueira-iwsg-2018, title = {IoT-Hub: New IoT data-platform for Virtual Research Environments}, author = {Filgueira, Rosa and Ferreira da Silva, Rafael and Deelman, Ewa and Christodoulou, Vyron and Krause, Amrey}, booktitle = {10th International Workshop on Science Gateways (IWSG 2018)}, year = {2018}, pages = {}, doi = {} } -
Gil, Y., Cobourn, K., Deelman, E., Duffy, C., Ferreira da Silva, R., Kemanian, A., Knoblock, C., Kumar, V., Peckham, S., Carvalho, L., Chiang, Y.-Y., Garijo, D., Khider, D., Khandelwal, A., Pahm, M., Pujara, J., Ratnakar, V., Stoica, M., & Vu, B. (2018). MINT: Model Integration Through Knowledge-Powered Data and Process Composition. 9th International Congress on Environmental Modelling and Software.
[BibTex]@inproceedings{gil-iemss-2018, title = {MINT: Model Integration Through Knowledge-Powered Data and Process Composition}, author = {Gil, Yolanda and Cobourn, Kelly and Deelman, Ewa and Duffy, Chris and Ferreira da Silva, Rafael and Kemanian, Armen and Knoblock, Craig and Kumar, Vipin and Peckham, Scott and Carvalho, Lucas and Chiang, Yao-Yi and Garijo, Daniel and Khider, Deborah and Khandelwal, Ankush and Pahm, Minh and Pujara, Jay and Ratnakar, Varun and Stoica, Maria and Vu, Binh}, booktitle = {9th International Congress on Environmental Modelling and Software}, year = {2018}, pages = {}, doi = {} } -
Glatard, T., Kiar, G., Aumentado-Armstrong, T., Beck, N., Bellec, P., Bernard, R., Bonnet, A., Brown, S. T., Camarasu-Pop, S., Cervenansky, F., Das, S., Ferreira da Silva, R., Flandin, G., Girard, P., & others. (2018). Boutiques: a flexible framework to integrate command-line applications in computing platforms. GigaScience, 7(5). https://doi.org/10.1093/gigascience/giy016
[BibTex]@article{glatard-gigascience-2018, title = {Boutiques: a flexible framework to integrate command-line applications in computing platforms}, author = {Glatard, Tristan and Kiar, Gregory and Aumentado-Armstrong, Tristan and Beck, Natacha and Bellec, Pierre and Bernard, R{\'e}mi and Bonnet, Axel and Brown, Shawn T and Camarasu-Pop, Sorina and Cervenansky, Fr{\'e}d{\'e}ric and Das, Samir and Ferreira da Silva, Rafael and Flandin, Guillaume and Girard, Pascal and others}, journal = {GigaScience}, volume = {7}, number = {5}, pages = {}, year = {2018}, doi = {10.1093/gigascience/giy016} } -
Tovar, B., Ferreira da Silva, R., Juve, G., Deelman, E., Allcock, W., Thain, D., & Livny, M. (2018). A Job Sizing Strategy for High-Throughput Scientific Workflows. IEEE Transactions on Parallel and Distributed Systems, 29(2), 240–253. https://doi.org/10.1109/TPDS.2017.2762310
[BibTex]@article{tovar-tpds-2017, title = {A Job Sizing Strategy for High-Throughput Scientific Workflows}, author = {Tovar, Benjamin and Ferreira da Silva, Rafael and Juve, Gideon and Deelman, Ewa and Allcock, William and Thain, Douglas and Livny, Miron}, journal = {IEEE Transactions on Parallel and Distributed Systems}, volume = {29}, number = {2}, pages = {240--253}, year = {2018}, doi = {10.1109/TPDS.2017.2762310} }
2017
-
Deelman, E., Carothers, C., Mandal, A., Tierney, B., Vetter, J. S., Baldin, I., Castillo, C., Juve, G., Król, D., Lynch, V., Mayer, B., Meredith, J., Proffen, T., Ruth, P., & Ferreira da Silva, R. (2017). PANORAMA: An Approach to Performance Modeling and Diagnosis of Extreme Scale Workflows. International Journal of High Performance Computing Applications, 31(1), 4–18. https://doi.org/10.1177/1094342015594515
[BibTex]@article{deelman-hpc-2015, title = {PANORAMA: An Approach to Performance Modeling and Diagnosis of Extreme Scale Workflows}, journal = {International Journal of High Performance Computing Applications}, volume = {31}, number = {1}, pages = {4--18}, year = {2017}, author = {Deelman, Ewa and Carothers, Christopher and Mandal, Anirban and Tierney, Brian and Vetter, Jeffrey S. and Baldin, Ilya and Castillo, Claris and Juve, Gideon and Kr\'ol, Dariusz and Lynch, Vickie and Mayer, Ben and Meredith, Jeremy and Proffen, Thomas and Ruth, Paul and Ferreira da Silva, Rafael}, doi = {10.1177/1094342015594515} } -
Ferreira da Silva, R., Callaghan, S., & Deelman, E. (2017). On the Use of Burst Buffers for Accelerating Data-Intensive Scientific Workflows. 12th Workshop on Workflows in Support of Large-Scale Science (WORKS’17). https://doi.org/10.1145/3150994.3151000
[BibTex]@inproceedings{ferreiradasilva-works-2017, title = {On the Use of Burst Buffers for Accelerating Data-Intensive Scientific Workflows}, author = {Ferreira da Silva, Rafael and Callaghan, Scott and Deelman, Ewa}, booktitle = {12th Workshop on Workflows in Support of Large-Scale Science (WORKS'17)}, year = {2017}, pages = {}, doi = {10.1145/3150994.3151000} } -
Ferreira da Silva, R., Filgueira, R., Pietri, I., Jiang, M., Sakellariou, R., & Deelman, E. (2017). A Characterization of Workflow Management Systems for Extreme-Scale Applications. Future Generation Computer Systems, 75, 228–238. https://doi.org/10.1016/j.future.2017.02.026
[BibTex]@article{ferreiradasilva-fgcs-2017, title = {A Characterization of Workflow Management Systems for Extreme-Scale Applications}, author = {Ferreira da Silva, Rafael and Filgueira, Rosa and Pietri, Ilia and Jiang, Ming and Sakellariou, Rizos and Deelman, Ewa}, journal = {Future Generation Computer Systems}, volume = {75}, number = {}, pages = {228--238}, year = {2017}, doi = {10.1016/j.future.2017.02.026} } -
Glatard, T., Rousseau, M.-E., Camarasu-Pop, S., Adalat, R., Beck, N., Das, S., Ferreira da Silva, R., Khalili-Mahani, N., Korkhov, V., Quirion, P.-O., Rioux, P., Olabarriaga, S. D., Bellec, P., & Evans, A. C. (2017). Software architectures to integrate workflow engines in science gateways. Future Generation Computer Systems, 75, 239–255. https://doi.org/10.1016/j.future.2017.01.005
[BibTex]@article{glatard-fgcs-2017, title = {Software architectures to integrate workflow engines in science gateways}, author = {Glatard, Tristan and Rousseau, Marc-Etienne and Camarasu-Pop, Sorina and Adalat, Reza and Beck, Natacha and Das, Samir and Ferreira da Silva, Rafael and Khalili-Mahani, Najmeh and Korkhov, Vladimir and Quirion, Pierre-Olivier and Rioux, Pierre and Olabarriaga, Silvia D. and Bellec, Pierre and Evans, Alan C.}, journal = {Future Generation Computer Systems}, volume = {75}, number = {}, pages = {239--255}, year = {2017}, doi = {10.1016/j.future.2017.01.005} } -
Lynch, V., Calvo, J. B., Deelman, E., Ferreira da Silva, R., Goswami, M., Hui, Y., Lingerfelt, E., & Vetter, J. (2017). Distributed Workflows for Modeling Experimental Data. 2017 IEEE High Performance Extreme Computing Conference (HPEC’17). https://doi.org/10.1109/HPEC.2017.8091071
[BibTex]@inproceedings{lynch-hpec-2017, title = {Distributed Workflows for Modeling Experimental Data}, author = {Lynch, Vickie and Calvo, Jose Borreguero and Deelman, Ewa and Ferreira da Silva, Rafael and Goswami, Monojoy and Hui, Yawei and Lingerfelt, Eric and Vetter, Jeffrey}, booktitle = {2017 IEEE High Performance Extreme Computing Conference (HPEC'17)}, year = {2017}, pages = {}, doi = {10.1109/HPEC.2017.8091071} } -
Mandal, A., Ruth, P., Baldin, I., Ferreira da Silva, R., & Deelman, E. (2017). Toward Prioritization of Data Flows for Scientific Workflows Using Virtual Software Defined Exchanges. First International Workshop on Workflow Science (WoWS 2017), 566–575. https://doi.org/10.1109/eScience.2017.92
[BibTex]@inproceedings{mandal-wows-2017, title = {Toward Prioritization of Data Flows for Scientific Workflows Using Virtual Software Defined Exchanges}, author = {Mandal, Anirban and Ruth, Paul and Baldin, Ilya and Ferreira da Silva, Rafael and Deelman, Ewa}, booktitle = {First International Workshop on Workflow Science (WoWS 2017)}, year = {2017}, pages = {566-575}, doi = {10.1109/eScience.2017.92} } -
Santana-Perez, I., Ferreira da Silva, R., Rynge, M., Deelman, E., Pérez-Hernández, M. S., & Corcho, O. (2017). Reproducibility of Execution Environments in Computational Science Using Semantics and Clouds. Future Generation Computer Systems, 67, 354–367. https://doi.org/10.1016/j.future.2015.12.017
[BibTex]@article{santanaperez-fgcs-2016, title = {Reproducibility of Execution Environments in Computational Science Using Semantics and Clouds}, author = {Santana-Perez, Idafen and Ferreira da Silva, Rafael and Rynge, Mats and Deelman, Ewa and P\'erez-Hern\'andez, Maria S. and Corcho, Oscar}, journal = {Future Generation Computer Systems}, volume = {67}, number = {}, pages = {354--367}, year = {2017}, doi = {10.1016/j.future.2015.12.017} } -
Taylor, I. J., Brinckman, A., Deelman, E., Ferreira da Silva, R., Gupta, S., Nabrzyski, J., Park, S., & Vahi, K. (2017). Accelerating Circuit Realization via a Collaborative Gateway of Innovations. 9th International Workshop on Science Gateways (IWSG 2017).
[BibTex]@inproceedings{taylor-iwsg-2017, title = {Accelerating Circuit Realization via a Collaborative Gateway of Innovations}, author = {Taylor, Ian J. and Brinckman, Adam and Deelman, Ewa and Ferreira da Silva, Rafael and Gupta, Sandeep and Nabrzyski, Jarek and Park, Soowang and Vahi, Karan}, booktitle = {9th International Workshop on Science Gateways (IWSG 2017)}, year = {2017}, pages = {}, doi = {} }
2016
-
Chen, W., Ferreira da Silva, R., Deelman, E., & Fahringer, T. (2016). Dynamic and Fault-Tolerant Clustering for Scientific Workflows. IEEE Transactions on Cloud Computing, 4(1), 49–62. https://doi.org/10.1109/TCC.2015.2427200
[BibTex]@article{chen-tcc-2015, title = {Dynamic and Fault-Tolerant Clustering for Scientific Workflows}, journal = {IEEE Transactions on Cloud Computing}, volume = {4}, number = {1}, pages = {49--62}, year = {2016}, author = {Chen, Weiwei and Ferreira da Silva, Rafael and Deelman, Ewa and Fahringer, Thomas}, doi = {10.1109/TCC.2015.2427200} } -
Deelman, E., Vahi, K., Rynge, M., Juve, G., Mayani, R., & Ferreira da Silva, R. (2016). Pegasus in the Cloud: Science Automation through Workflow Technologies. IEEE Internet Computing, 20(1), 70–76. https://doi.org/10.1109/MIC.2016.15
[BibTex]@article{deelman-ic-2016, title = {Pegasus in the Cloud: Science Automation through Workflow Technologies}, author = {Deelman, Ewa and Vahi, Karan and Rynge, Mats and Juve, Gideon and Mayani, Rajiv and Ferreira da Silva, Rafael}, journal = {IEEE Internet Computing}, volume = {20}, number = {1}, pages = {70--76}, year = {2016}, doi = {10.1109/MIC.2016.15} } -
Ferreira da Silva, R., Deelman, E., Filgueira, R., Vahi, K., Rynge, M., Mayani, R., & Mayer, B. (2016). Automating Environmental Computing Applications with Scientific Workflows. Environmental Computing Workshop, IEEE 12th International Conference on e-Science, 400–406. https://doi.org/10.1109/eScience.2016.7870926
[BibTex]@inproceedings{ferreiradasilva-ecw-2016, author = {Ferreira da Silva, Rafael and Deelman, Ewa and Filgueira, Rosa and Vahi, Karan and Rynge, Mats and Mayani, Rajiv and Mayer, Benjamin}, title = {Automating Environmental Computing Applications with Scientific Workflows}, year = {2016}, booktitle = {Environmental Computing Workshop, IEEE 12th International Conference on e-Science}, series = {ECW'16}, doi = {10.1109/eScience.2016.7870926}, pages = {400--406} } -
Ferreira da Silva, R., Filgueira, R., Deelman, E., Pairo-Castineira, E., Overton, I. M., & Atkinson, M. (2016). Using Simple PID Controllers to Prevent and Mitigate Faults in Scientific Workflows. 11th Workflows in Support of Large-Scale Science, 15–24.
[BibTex]@inproceedings{ferreiradasilva-works-2016, author = {Ferreira da Silva, Rafael and Filgueira, Rosa and Deelman, Ewa and Pairo-Castineira, Erola and Overton, Ian Michael and Atkinson, Malcolm}, title = {Using Simple PID Controllers to Prevent and Mitigate Faults in Scientific Workflows}, year = {2016}, booktitle = {11th Workflows in Support of Large-Scale Science}, series = {WORKS'16}, pages = {15--24} } -
Filgueira, R., Ferreira da Silva, R., Krause, A., Deelman, E., & Atkinson, M. (2016). Asterism: Pegasus and dispel4py hybrid workflows for data-intensive science. 7th International Workshop on Data-Intensive Computing in the Clouds, 1–8. https://doi.org/10.1109/DataCloud.2016.004
[BibTex]@inproceedings{filgueira-datacloud-2016, author = {Filgueira, Rosa and Ferreira da Silva, Rafael and Krause, Amrey and Deelman, Ewa and Atkinson, Malcolm}, title = {Asterism: Pegasus and dispel4py hybrid workflows for data-intensive science}, year = {2016}, booktitle = {7th International Workshop on Data-Intensive Computing in the Clouds}, series = {DataCloud'16}, doi = {10.1109/DataCloud.2016.004}, pages = {1--8} } -
Krol, D., Ferreira da Silva, R., Deelman, E., & Lynch, V. E. (2016). Workflow Performance Profiles: Development and Analysis. In F. Desprez, P.-F. Dutot, C. Kaklamanis, L. Marchal, K. Molitorisz, L. Ricci, V. Scarano, M. A. Vega-Rodríguez, A. L. Varbanescu, S. Hunold, S. L. Scott, S. Lankes, & J. Weidendorfer (Eds.), Euro-Par 2016: Parallel Processing Workshops: Euro-Par 2016 International Workshops (pp. 108–120). https://doi.org/10.1007/978-3-319-58943-5_9
[BibTex]@incollection{krol-heteropar-2016, title = {Workflow Performance Profiles: Development and Analysis}, author = {Krol, Dariusz and Ferreira da Silva, Rafael and Deelman, Ewa and Lynch, Vickie E.}, booktitle = {Euro-Par 2016: Parallel Processing Workshops: Euro-Par 2016 International Workshops}, volume = {}, series = {Lecture Notes in Computer Science}, editor = {Desprez, Fr{\'e}d{\'e}ric and Dutot, Pierre-Fran{\c{c}}ois and Kaklamanis, Christos and Marchal, Loris and Molitorisz, Korbinian and Ricci, Laura and Scarano, Vittorio and Vega-Rodr{\'i}guez, Miguel A. and Varbanescu, Ana Lucia and Hunold, Sascha and Scott, Stephen L. and Lankes, Stefan and Weidendorfer, Josef}, doi = {10.1007/978-3-319-58943-5_9}, year = {2016}, pages = {108--120} } -
Krol, D., Kitowski, J., Ferreira da Silva, R., Juve, G., Vahi, K., Rynge, M., & Deelman, E. (2016). Science Automation in Practice: Performance Data Farming in Workflows. 21st IEEE International Conference on Emerging Technologies and Factory Automation. https://doi.org/10.1109/ETFA.2016.7733677
[BibTex]@inproceedings{krol-etfa-2016, author = {Krol, Dariusz and Kitowski, Jacek and Ferreira da Silva, Rafael and Juve, Gideon and Vahi, Karan and Rynge, Mats and Deelman, Ewa}, title = {Science Automation in Practice: Performance Data Farming in Workflows}, booktitle = {21st IEEE International Conference on Emerging Technologies and Factory Automation}, series = {ETFA'16}, year = {2016}, doi = {10.1109/ETFA.2016.7733677}, pages = {} } -
Mandal, A., Ruth, P., Baldin, I., Krol, D., Juve, G., Mayani, R., Ferreira da Silva, R., Deelman, E., Meredith, J., Vetter, J., Lynch, V., Mayer, B., Wynne III, J., Blanco, M., Carothers, C., LaPre, J., & Tierney, B. (2016). Toward an End-to-end Framework for Modeling, Monitoring, and Anomaly Detection for Scientific Workflows. Workshop on Large-Scale Parallel Processing, 1370–1379. https://doi.org/10.1109/IPDPSW.2016.202
[BibTex]@inproceedings{mandal-lspp-2016, author = {Mandal, Anirban and Ruth, Paul and Baldin, Ilya and Krol, Dariusz and Juve, Gideon and Mayani, Rajiv and Ferreira da Silva, Rafael and Deelman, Ewa and Meredith, Jeremy and Vetter, Jeffrey and Lynch, Vickie and Mayer, Ben and Wynne III, James and Blanco, Mark and Carothers, Chris and LaPre, Justin and Tierney, Brian}, title = {Toward an End-to-end Framework for Modeling, Monitoring, and Anomaly Detection for Scientific Workflows}, booktitle = {Workshop on Large-Scale Parallel Processing}, series = {LSPP'16}, year = {2016}, doi = {10.1109/IPDPSW.2016.202}, pages = {1370--1379} } -
Nawaz, H., Juve, G., Ferreira da Silva, R., & Deelman, E. (2016). Performance Analysis of an I/O-Intensive Workflow executing on Google Cloud and Amazon Web Services. 18th Workshop on Advances in Parallel and Distributed Computational Models, 535–544. https://doi.org/10.1109/IPDPSW.2016.90
[BibTex]@inproceedings{nawaz-apdcm-2016, author = {Nawaz, Hassan and Juve, Gideon and Ferreira da Silva, Rafael and Deelman, Ewa}, title = {Performance Analysis of an I/O-Intensive Workflow executing on Google Cloud and Amazon Web Services}, booktitle = {18th Workshop on Advances in Parallel and Distributed Computational Models}, series = {APDCM'16}, year = {2016}, doi = {10.1109/IPDPSW.2016.90}, pages = {535--544} } -
Schlagkamp, S., Ferreira da Silva, R., Allcock, W., Deelman, E., & Schwiegelshohn, U. (2016). Consecutive Job Submission Behavior at Mira Supercomputer. 25th ACM International Symposium on High-Performance Parallel and Distributed Computing, 93–96. https://doi.org/10.1145/2907294.2907314
[BibTex]@inproceedings{schlagkamp-hpdc-2016, author = {Schlagkamp, Stephan and Ferreira da Silva, Rafael and Allcock, William and Deelman, Ewa and Schwiegelshohn, Uwe}, title = {Consecutive Job Submission Behavior at Mira Supercomputer}, booktitle = {25th ACM International Symposium on High-Performance Parallel and Distributed Computing}, series = {HPDC'16}, year = {2016}, doi = {10.1145/2907294.2907314}, pages = {93--96} } -
Schlagkamp, S., Ferreira da Silva, R., Deelman, E., & Schwiegelshohn, U. (2016). Understanding User Behavior: from HPC to HTC. Procedia Computer Science, 2241–2245. https://doi.org/10.1016/j.procs.2016.05.397
[BibTex]@article{schlagkamp-iccs-2016, author = {Schlagkamp, Stephan and Ferreira da Silva, Rafael and Deelman, Ewa and Schwiegelshohn, Uwe}, title = {Understanding User Behavior: from HPC to HTC}, journal = {Procedia Computer Science}, series = {ICCS'16}, year = {2016}, doi = {10.1016/j.procs.2016.05.397}, pages = {2241--2245}, note = {International Conference on Computational Science 2016, \{ICCS\} 2016} } -
Schlagkamp, S., Ferreira da Silva, R., Renker, J., & Rinkenauer, G. (2016). Analyzing Users in Parallel Computing: A User-Oriented Study. 2016 International Conference on High Performance Computing & Simulation, 395–402. https://doi.org/10.1109/HPCSim.2016.7568362
[BibTex]@inproceedings{schlagkamp-hpcs-2016, author = {Schlagkamp, Stephan and Ferreira da Silva, Rafael and Renker, Johanna and Rinkenauer, Gerhard}, title = {Analyzing Users in Parallel Computing: A User-Oriented Study}, booktitle = {2016 International Conference on High Performance Computing \& Simulation}, series = {HPCS'16}, year = {2016}, doi = {10.1109/HPCSim.2016.7568362}, pages = {395--402} } -
Schlagkamp, S., Hofmann, M., Eufinger, L., & Ferreira da Silva, R. (2016). Increasing Waiting Time Satisfaction in Parallel Job Scheduling via a Flexible MILP Approach. 2016 International Conference on High Performance Computing & Simulation, 164–171. https://doi.org/10.1109/HPCSim.2016.7568331
[BibTex]@inproceedings{schlagkamp-hpcs-2016a, author = {Schlagkamp, Stephan and Hofmann, Matthias and Eufinger, Lars and Ferreira da Silva, Rafael}, title = {Increasing Waiting Time Satisfaction in Parallel Job Scheduling via a Flexible MILP Approach}, booktitle = {2016 International Conference on High Performance Computing \& Simulation}, series = {HPCS'16}, year = {2016}, doi = {10.1109/HPCSim.2016.7568331}, pages = {164--171} }
2015
-
Chen, W., Ferreira da Silva, R., Deelman, E., & Sakellariou, R. (2015). Using Imbalance Metrics to Optimize Task Clustering in Scientific Workflow Executions. Future Generation Computer Systems, 46(0), 69–84. https://doi.org/10.1016/j.future.2014.09.014
[BibTex]@article{chen-fgcs-2014, title = {Using Imbalance Metrics to Optimize Task Clustering in Scientific Workflow Executions}, journal = {Future Generation Computer Systems}, volume = {46}, number = {0}, pages = {69--84}, year = {2015}, doi = {10.1016/j.future.2014.09.014}, author = {Chen, Weiwei and Ferreira da Silva, Rafael and Deelman, Ewa and Sakellariou, Rizos} } -
Deelman, E., Vahi, K., Juve, G., Rynge, M., Callaghan, S., Maechling, P. J., Mayani, R., Chen, W., Ferreira da Silva, R., Livny, M., & Wenger, K. (2015). Pegasus, a Workflow Management System for Science Automation. Future Generation Computer Systems, 46(0), 17–35. https://doi.org/10.1016/j.future.2014.10.008
[BibTex]@article{deelman-fgcs-2015, title = {Pegasus, a Workflow Management System for Science Automation}, journal = {Future Generation Computer Systems}, volume = {46}, number = {0}, pages = {17--35}, year = {2015}, doi = {10.1016/j.future.2014.10.008}, author = {Deelman, Ewa and Vahi, Karan and Juve, Gideon and Rynge, Mats and Callaghan, Scott and Maechling, Phil J. and Mayani, Rajiv and Chen, Weiwei and Ferreira da Silva, Rafael and Livny, Miron and Wenger, Kent} } -
Ferreira da Silva, R., Glatard, T., & Desprez, F. (2015). Self-Managing of Operational Issues for Grid Computing: The Case of The Virtual Imaging Platform. In S. Bagchi (Ed.), Emerging Research in Cloud Distributed Computing Systems (pp. 187–221). IGI Global. https://doi.org/10.4018/978-1-4666-8213-9.ch006
[BibTex]@incollection{ferreiradasilva-igi-2015, editor = {Bagchi, Susmit}, booktitle = {Emerging Research in Cloud Distributed Computing Systems}, title = {Self-Managing of Operational Issues for Grid Computing: The Case of The Virtual Imaging Platform}, pages = {187--221}, publisher = {IGI Global}, year = {2015}, author = {Ferreira da Silva, Rafael and Glatard, Tristan and Desprez, Fr\'{e}d\'{e}ric}, doi = {10.4018/978-1-4666-8213-9.ch006} } -
Ferreira da Silva, R., Juve, G., Rynge, M., Deelman, E., & Livny, M. (2015). Online Task Resource Consumption Prediction for Scientific Workflows. Parallel Processing Letters, 25(3). https://doi.org/10.1142/S0129626415410030
[BibTex]@article{ferreiradasilva-ppl-2015, title = {Online Task Resource Consumption Prediction for Scientific Workflows}, author = {Ferreira da Silva, Rafael and Juve, Gideon and Rynge, Mats and Deelman, Ewa and Livny, Miron}, journal = {Parallel Processing Letters}, volume = {25}, number = {3}, pages = {}, year = {2015}, doi = {10.1142/S0129626415410030} } -
Ferreira da Silva, R., Rynge, M., Juve, G., Sfiligoi, I., Deelman, E., Letts, J., Würthwein, F., & Livny, M. (2015). Characterizing a High Throughput Computing Workload: The Compact Muon Solenoid (CMS) Experiment at LHC. Procedia Computer Science, 51, 39–48. https://doi.org/10.1016/j.procs.2015.05.190
[BibTex]@article{ferreiradasilva-iccs-2015, title = {Characterizing a High Throughput Computing Workload: The Compact Muon Solenoid ({CMS}) Experiment at {LHC}}, author = {Ferreira da Silva, Rafael and Rynge, Mats and Juve, Gideon and Sfiligoi, Igor and Deelman, Ewa and Letts, James and W\"urthwein, Frank and Livny, Miron}, journal = {Procedia Computer Science}, year = {2015}, volume = {51}, pages = {39--48}, note = {International Conference On Computational Science, \{ICCS\} 2015 Computational Science at the Gates of Nature}, doi = {10.1016/j.procs.2015.05.190} } -
Glatard, T., Ferreira da Silva, R., Boujelben, N., Adalat, R., Beck, N., Rioux, P., Rousseau, M.-E., Deelman, E., & Evans, A. C. (2015). Boutiques: an application-sharing system based on Linux containers. NeuroInformatics 2015. https://doi.org/10.3389/conf.fnins.2015.91.00012
[BibTex]@inproceedings{glatard-neuroinformatics-2015, author = {Glatard, Tristan and Ferreira da Silva, Rafael and Boujelben, Nouha and Adalat, Reza and Beck, Natacha and Rioux, Pierre and Rousseau, Marc-Etienne and Deelman, Ewa and Evans, Alan C.}, title = {Boutiques: an application-sharing system based on Linux containers}, booktitle = {NeuroInformatics 2015}, year = {2015}, doi = {10.3389/conf.fnins.2015.91.00012} } -
Glatard, T., Lewis, L. B., Ferreira da Silva, R., Adalat, R., Beck, N., Lepage, C., Rioux, P., Rousseau, M.-E., Sherif, T., Deelman, E., Khalili-Mahani, N., & Evans, A. C. (2015). Reproducibility of neuroimaging analyses across operating systems. Frontiers in Neuroinformatics, 9(12). https://doi.org/10.3389/fninf.2015.00012
[BibTex]@article{glatard-fneuroinformatics-2015, title = {Reproducibility of neuroimaging analyses across operating systems}, journal = {Frontiers in Neuroinformatics}, volume = {9}, number = {12}, pages = {}, year = {2015}, doi = {10.3389/fninf.2015.00012}, author = {Glatard, Tristan and Lewis, Lindsay Burke and Ferreira da Silva, Rafael and Adalat, Reza and Beck, Natacha and Lepage, Claude and Rioux, Pierre and Rousseau, Marc-Etienne and Sherif, Tarek and Deelman, Ewa and Khalili-Mahani, Najmeh and Evans, Alan Charles} } -
Howison, J., Deelman, E., McLennan, M. J., Ferreira da Silva, R., & Herbsleb, J. D. (2015). Understanding the scientific software ecosystem and its impact: Current and future measures. Research Evaluation, 24(4), 454–470. https://doi.org/10.1093/reseval/rvv014
[BibTex]@article{howison-reseval-2015, title = {Understanding the scientific software ecosystem and its impact: Current and future measures}, journal = {Research Evaluation}, volume = {24}, number = {4}, pages = {454--470}, year = {2015}, author = {Howison, James and Deelman, Ewa and McLennan, Michael J. and Ferreira da Silva, Rafael and Herbsleb, James D.}, doi = {10.1093/reseval/rvv014} } -
Juve, G., Tovar, B., Ferreira da Silva, R., Król, D., Thain, D., Deelman, E., Allcock, W., & Livny, M. (2015). Practical Resource Monitoring for Robust High Throughput Computing. 2nd Workshop on Monitoring and Analysis for High Performance Computing Systems Plus Applications, 650–657. https://doi.org/10.1109/CLUSTER.2015.115
[BibTex]@inproceedings{juve-hpcmaspa-2015, title = {Practical Resource Monitoring for Robust High Throughput Computing}, author = {Juve, Gideon and Tovar, Benjamin and Ferreira da Silva, Rafael and Kr\'ol, Dariusz and Thain, Douglas and Deelman, Ewa and Allcock, William and Livny, Miron}, booktitle = {2nd Workshop on Monitoring and Analysis for High Performance Computing Systems Plus Applications}, series = {HPCMASPA'15}, year = {2015}, doi = {10.1109/CLUSTER.2015.115}, pages = {650--657} } -
Mayer, B., Worley, P., Ferreira da Silva, R., & Gaddis, A. (2015). Climate Science Performance, Data and Productivity on Titan. Cray User Group Conference.
[BibTex]@inproceedings{mayer-cug-2015, title = {Climate Science Performance, Data and Productivity on Titan}, author = {Mayer, Benjamin and Worley, Patrick and Ferreira da Silva, Rafael and Gaddis, Abigail}, booktitle = {Cray User Group Conference}, year = {2015} } -
Oda, R., Cordeiro, D., Ferreira da Silva, R., Deelman, E., & Braghetto, K. (2015). The Case for Resource Sharing in Scientific Workflow Executions. XVI Simposio Em Sistemas Computacionais De Alto Desempenho.
[BibTex]@inproceedings{oda-wscad-2015, title = {The Case for Resource Sharing in Scientific Workflow Executions}, author = {Oda, Ricardo and Cordeiro, Daniel and Ferreira da Silva, Rafael and Deelman, Ewa and Braghetto, Kelly}, booktitle = {XVI Simposio em Sistemas Computacionais de Alto Desempenho}, series = {WSCAD'15}, year = {2015} }
2014
-
Ferreira da Silva, R., Chen, W., Juve, G., Vahi, K., & Deelman, E. (2014). Community Resources for Enabling and Evaluating Research in Distributed Scientific Workflows. 10th IEEE International Conference on e-Science, 177–184. https://doi.org/10.1109/eScience.2014.44
[BibTex]@inproceedings{ferreiradasilva-escience-2014, title = {Community Resources for Enabling and Evaluating Research in Distributed Scientific Workflows}, author = {Ferreira da Silva, Rafael and Chen, Weiwei and Juve, Gideon and Vahi, Karan and Deelman, Ewa}, booktitle = {10th {IEEE} International Conference on e-Science}, series = {eScience'14}, year = {2014}, pages = {177--184}, doi = {10.1109/eScience.2014.44} } -
Ferreira da Silva, R., Fahringer, T., Durillo, J. J., & Deelman, E. (2014). A Unified Approach for Modeling and Optimization of Energy, Makespan and Reliability for Scientific Workflows on Large-Scale Computing Infrastructures. Workshop on Modeling & Simulation of Systems and Applications.
[BibTex]@inproceedings{ferreiradasilva-modsim-2014, title = {A Unified Approach for Modeling and Optimization of Energy, Makespan and Reliability for Scientific Workflows on Large-Scale Computing Infrastructures}, author = {Ferreira da Silva, Rafael and Fahringer, Thomas and Durillo, Juan J. and Deelman, Ewa}, booktitle = {Workshop on Modeling \& Simulation of Systems and Applications}, year = {2014}, pages = {} } -
Ferreira da Silva, R., Glatard, T., & Desprez, F. (2014). Controlling fairness and task granularity in distributed, online, non-clairvoyant workflow executions. Concurrency and Computation: Practice and Experience, 26(14), 2347–2366. https://doi.org/10.1002/cpe.3303
[BibTex]@article{ferreiradasilva-ccpe-2014, title = {Controlling fairness and task granularity in distributed, online, non-clairvoyant workflow executions}, journal = {Concurrency and Computation: Practice and Experience}, volume = {26}, number = {14}, pages = {2347--2366}, year = {2014}, issn = {1532-0634}, doi = {10.1002/cpe.3303}, author = {Ferreira da Silva, Rafael and Glatard, Tristan and Desprez, Fr\'{e}d\'{e}ric} } -
Glatard, T., Lewis, L. B., Ferreira da Silva, R., Rousseau, M.-E., Lepage, C., Rioux, P., Mahani, N., Deelman, E., & Evans, A. C. (2014). Extending provenance information in CBRAIN to address reproducibility issues across computing platforms. Frontiers in Neuroinformatics, 76. https://doi.org/10.3389/conf.fninf.2014.18.00076
[BibTex]@article{glatard-neuroinformatics-2014, author = {Glatard, Tristan and Lewis, Lindsay B and Ferreira da Silva, Rafael and Rousseau, Marc-Etienne and Lepage, Claude and Rioux, Pierre and Mahani, Najmeh and Deelman, Ewa and Evans, Alan C}, title = {Extending provenance information in CBRAIN to address reproducibility issues across computing platforms}, journal = {Frontiers in Neuroinformatics}, volume = {}, year = {2014}, number = {76}, doi = {10.3389/conf.fninf.2014.18.00076}, issn = {1662-5196} } -
James, D., Wilkins-Diehr, N., Stodden, V., Colbry, D., Rosales, C., Fahey, M., Shi, J., Ferreira da Silva, R., Lee, K., Roskies, R., Loewe, L., Lindsey, S., Kooper, R., Barba, L., Bailey, D., Borwein, J., Corcho, O., Deelman, E., Dietze, M., … Suriarachchi, I. (2014). Standing Together for Reproducibility in Large-Scale Computing: Report on reproducibility@XSEDE. http://arxiv.org/abs/1412.5557
[BibTex]@misc{james-xsede-2014, title = {Standing Together for Reproducibility in Large-Scale Computing: Report on reproducibility@{XSEDE}}, year = {2014}, url = {http://arxiv.org/abs/1412.5557}, author = {James, Doug and Wilkins-Diehr, Nancy and Stodden, Victoria and Colbry, Dirk and Rosales, Carlos and Fahey, Mark and Shi, Justin and Ferreira da Silva, Rafael and Lee, Kyo and Roskies, Ralph and Loewe, Laurence and Lindsey, Susan and Kooper, Rob and Barba, Lorena and Bailey, David and Borwein, Jonathan and Corcho, Oscar and Deelman, Ewa and Dietze, Michael and Gilbert, Benjamin and Harkes, Jan and Keele, Seth and Kumar, Praveen and Lee, Jong and Linke, Erika and Marciano, Richard and Marini, Luigi and Mattman, Chris and Mattson, Dave and {McHenry}, Kenton and {McLay}, Robert and Miguez, Sheila and Minsker, Barbara and Perez-Hernandez, Maria and Ryan, Dan and Rynge, Mats and Santana-Perez, Idafen and Satyanarayanan, Mahadev and Clair, Gloriana St and Webster, Keith and Hovig, Elvind and Katz, Dan and Kay, Sophie and Sandve, Geir and Skinner, David and Allen, Gabrielle and Cazes, John and Cho, Kym Won and Fonseca, Jim and Hwang, Lorraine and Koesterke, Lars and Patel, Pragnesh and Pouchard, Line and Seidel, Ed and Suriarachchi, Isuru} } -
Juve, G., Tovar, B., Ferreira da Silva, R., Robinson, C., Thain, D., Deelman, E., Allcock, W., & Livny, M. (2014). Practical Resource Monitoring for Robust High Throughput Computing. University of Southern California.
[BibTex]@techreport{juve-usc-2014, author = {Juve, Gideon and Tovar, Benjamin and Ferreira da Silva, Rafael and Robinson, Casey and Thain, Douglas and Deelman, Ewa and Allcock, William and Livny, Miron}, title = {Practical Resource Monitoring for Robust High Throughput Computing}, institution = {University of Southern California}, year = {2014}, location = {Los Angeles, California}, keywords = {Semantic Metadata, Scientific Workflow, Reproducibility}, howpublished = {http://www.cs.usc.edu/assets/007/92466.pdf} } -
Malawski, M., Nowakowski, P., Gubala, T., Kasztelnik, M., Bubak, M., Ferreira da Silva, R., Deelman, E., & Nabrzyski, J. (2014). Experiments with Complex Scientific Applications on Hybrid Cloud Infrastructures. NSFCloud Workshop on Experimental Support for Cloud Computing.
[BibTex]@inproceedings{malawski-nsfcloud-2014, title = {Experiments with Complex Scientific Applications on Hybrid Cloud Infrastructures}, year = {2014}, author = {Malawski, Maciej and Nowakowski, Piotr and Gubala, Tomasz and Kasztelnik, Marek and Bubak, Marian and Ferreira da Silva, Rafael and Deelman, Ewa and Nabrzyski, Jarek}, booktitle = {NSFCloud Workshop on Experimental Support for Cloud Computing}, pages = {} } -
Santana-Perez, I., Ferreira da Silva, R., Rynge, M., Deelman, E., Pérez-Hernández, M. S., & Corcho, O. (2014). A Semantic-Based Approach to Attain Reproducibility of Computational Environments in Scientific Workflows: A Case Study. In L. Lopes, J. Žilinskas, A. Costan, R. G. Cascella, G. Kecskemeti, E. Jeannot, M. Cannataro, L. Ricci, S. Benkner, S. Petit, V. Scarano, J. Gracia, S. Hunold, S. L. Scott, S. Lankes, C. Lengauer, J. Carretero, J. Breitbart, & M. Alexander (Eds.), Euro-Par 2014: Parallel Processing Workshops (Vol. 8805, pp. 452–463). https://doi.org/10.1007/978-3-319-14325-5_39
[BibTex]@incollection{santanaperez-reppar-2014, title = {A Semantic-Based Approach to Attain Reproducibility of Computational Environments in Scientific Workflows: A Case Study}, author = {Santana-Perez, Idafen and Ferreira da Silva, Rafael and Rynge, Mats and Deelman, Ewa and P\'erez-Hern\'andez, Mar\'ia S. and Corcho, Oscar}, booktitle = {Euro-Par 2014: Parallel Processing Workshops}, volume = {8805}, series = {Lecture Notes in Computer Science}, editor = {Lopes, Lu\'is and \v{Z}ilinskas, Julius and Costan, Alexandru and Cascella, Roberto G. and Kecskemeti, Gabor and Jeannot, Emmanuel and Cannataro, Mario and Ricci, Laura and Benkner, Siegfried and Petit, Salvador and Scarano, Vittorio and Gracia, Jos\'e and Hunold, Sascha and Scott, StephenL. and Lankes, Stefan and Lengauer, Christian and Carretero, Jesus and Breitbart, Jens and Alexander, Michael}, doi = {10.1007/978-3-319-14325-5_39}, year = {2014}, pages = {452--463} } -
Santana-Perez, I., Ferreira da Silva, R., Rynge, M., Deelman, E., Pérez-Hernández, M. S., & Corcho, O. (2014). Leveraging Semantics to Improve Reproducibility in Scientific Workflows. https://www.xsede.org/documents/659353/703287/xsede14_santana-perez.pdf.
[BibTex]@misc{santanaperez-xsede-2014, author = {Santana-Perez, Idafen and Ferreira da Silva, Rafael and Rynge, Mats and Deelman, Ewa and P\'erez-Hern\'andez, Mar\'ia S. and Corcho, Oscar}, title = {Leveraging Semantics to Improve Reproducibility in Scientific Workflows}, note = {Reproducibility@XSEDE}, year = {2014}, location = {Atlanta, Georgia}, keywords = {Semantic Metadata, Scientific Workflow, Reproducibility}, howpublished = {https://www.xsede.org/documents/659353/703287/xsede14_santana-perez.pdf} } -
Srinivasan, S., Juve, G., Ferreira da Silva, R., Vahi, K., & Deelman, E. (2014). A Cleanup Algorithm for Implementing Storage Constraints in Scientific Workflow Executions. 9th Workshop on Workflows in Support of Large-Scale Science, 41–49. https://doi.org/10.1109/WORKS.2014.8
[BibTex]@inproceedings{srinivasan-works-2014, title = {A Cleanup Algorithm for Implementing Storage Constraints in Scientific Workflow Executions}, author = {Srinivasan, Sudarshan and Juve, Gideon and Ferreira da Silva, Rafael and Vahi, Karan and Deelman, Ewa}, booktitle = {9th Workshop on Workflows in Support of Large-Scale Science}, series = {WORKS'14}, year = {2014}, pages = {41--49}, doi = {10.1109/WORKS.2014.8} }
2013
-
Azarnoosh, S., Rynge, M., Juve, G., Deelman, E., Niec, M., Malawski, M., & Ferreira da Silva, R. (2013). Introducing PRECIP: an API for Managing Repeatable Experiments in the Cloud. IEEE 5th International Conference on Cloud Computing Technology and Science, 2, 19–26. https://doi.org/10.1109/CloudCom.2013.98
[BibTex]@inproceedings{azarnoosh-crc-2013, author = {Azarnoosh, Sepideh and Rynge, Mats and Juve, Gideon and Deelman, Ewa and Niec, Michal and Malawski, Maciej and Ferreira da Silva, Rafael}, title = {Introducing PRECIP: an API for Managing Repeatable Experiments in the Cloud}, year = {2013}, booktitle = {IEEE 5th International Conference on Cloud Computing Technology and Science}, series = {CloudCom}, volume = {2}, pages = {19--26}, doi = {10.1109/CloudCom.2013.98} } -
Camarasu-Pop, S., Glatard, T., Ferreira da Silva, R., Gueth, P., Sarrut, D., & Benoit-Cattin, H. (2013). Monte Carlo simulation on heterogeneous distributed systems: A computing framework with parallel merging and checkpointing strategies. Future Generation Computer Systems, 29(3), 728–738. https://doi.org/10.1016/j.future.2012.09.003
[BibTex]@article{camarasupop-fgcs-2013, title = {Monte Carlo simulation on heterogeneous distributed systems: A computing framework with parallel merging and checkpointing strategies}, journal = {Future Generation Computer Systems}, volume = {29}, number = {3}, pages = {728--738}, year = {2013}, note = {Special Section: Recent Developments in High Performance Computing and Security}, doi = {10.1016/j.future.2012.09.003}, author = {Camarasu-Pop, Sorina and Glatard, Tristan and Ferreira da Silva, Rafael and Gueth, Pierre and Sarrut, David and Benoit-Cattin, Hugues} } -
Chen, W., Ferreira da Silva, R., Deelman, E., & Sakellariou, R. (2013). Balanced Task Clustering in Scientific Workflows. IEEE 9th International Conference on EScience, 188–195. https://doi.org/10.1109/eScience.2013.40
[BibTex]@inproceedings{chen-escience-2013, author = {Chen, Weiwei and Ferreira da Silva, Rafael and Deelman, Ewa and Sakellariou, Rizos}, booktitle = {IEEE 9th International Conference on eScience}, series = {eScience'13}, title = {Balanced Task Clustering in Scientific Workflows}, year = {2013}, pages = {188--195}, doi = {10.1109/eScience.2013.40} } -
Ferreira da Silva, R. (2013). A science-gateway for workflow executions: online and non-clairvoyant self-healing of workflow executions on grids [PhD thesis]. Institut National des Sciences Appliquées de Lyon (INSA-Lyon).
[BibTex]@phdthesis{ferreiradasilva-thesis-2013, title = {A science-gateway for workflow executions: online and non-clairvoyant self-healing of workflow executions on grids}, pagetotal = {155}, school = {Institut National des Sciences Appliquées de Lyon ({INSA}-Lyon)}, author = {Ferreira da Silva, Rafael}, year = {2013} } -
Ferreira da Silva, R., & Glatard, T. (2013). A Science-Gateway Workload Archive to Study Pilot Jobs, User Activity, Bag of Tasks, Task Sub-steps, and Workflow Executions. In I. Caragiannis, M. Alexander, R. M. Badia, M. Cannataro, A. Costan, M. Danelutto, F. Desprez, B. Krammer, J. Sahuquillo, S. L. Scott, & J. Weidendorfer (Eds.), Euro-Par 2012: Parallel Processing Workshops (Vol. 7640, pp. 79–88). https://doi.org/10.1007/978-3-642-36949-0_10
[BibTex]@incollection{ferreiradasilva-cgws-2013, year = {2013}, booktitle = {Euro-Par 2012: Parallel Processing Workshops}, volume = {7640}, series = {Lecture Notes in Computer Science}, editor = {Caragiannis, Ioannis and Alexander, Michael and Badia, RosaMaria and Cannataro, Mario and Costan, Alexandru and Danelutto, Marco and Desprez, Fr\'ed\'eric and Krammer, Bettina and Sahuquillo, Julio and Scott, StephenL. and Weidendorfer, Josef}, doi = {10.1007/978-3-642-36949-0_10}, title = {A Science-Gateway Workload Archive to Study Pilot Jobs, User Activity, Bag of Tasks, Task Sub-steps, and Workflow Executions}, author = {Ferreira da Silva, Rafael and Glatard, Tristan}, pages = {79--88} } -
Ferreira da Silva, R., Glatard, T., & Desprez, F. (2013). On-Line, Non-clairvoyant Optimization of Workflow Activity Granularity on Grids. In F. Wolf, B. Mohr, & D. Mey (Eds.), Euro-Par 2013 Parallel Processing (Vol. 8097, pp. 255–266). https://doi.org/10.1007/978-3-642-40047-6_28
[BibTex]@incollection{ferreiradasilva-europar-2013-granularity, year = {2013}, booktitle = {Euro-Par 2013 Parallel Processing}, volume = {8097}, series = {Lecture Notes in Computer Science}, editor = {Wolf, Felix and Mohr, Bernd and Mey, Dieter}, doi = {10.1007/978-3-642-40047-6_28}, title = {On-Line, Non-clairvoyant Optimization of Workflow Activity Granularity on Grids}, author = {Ferreira da Silva, Rafael and Glatard, Tristan and Desprez, Fr\'ed\'eric}, pages = {255--266} } -
Ferreira da Silva, R., Glatard, T., & Desprez, F. (2013). Workflow Fairness Control on Online and Non-clairvoyant Distributed Computing Platforms. In F. Wolf, B. Mohr, & D. Mey (Eds.), Euro-Par 2013 Parallel Processing (Vol. 8097, pp. 102–113). https://doi.org/10.1007/978-3-642-40047-6_13
[BibTex]@incollection{ferreiradasilva-europar-2013-fairness, year = {2013}, booktitle = {Euro-Par 2013 Parallel Processing}, volume = {8097}, series = {Lecture Notes in Computer Science}, editor = {Wolf, Felix and Mohr, Bernd and Mey, Dieter}, doi = {10.1007/978-3-642-40047-6_13}, title = {Workflow Fairness Control on Online and Non-clairvoyant Distributed Computing Platforms}, author = {Ferreira da Silva, Rafael and Glatard, Tristan and Desprez, Fr\'ed\'eric}, pages = {102--113} } -
Ferreira da Silva, R., Glatard, T., & Desprez, F. (2013). Self-healing of workflow activity incidents on distributed computing infrastructures. Future Generation Computer Systems, 29(8), 2284–2294. https://doi.org/10.1016/j.future.2013.06.012
[BibTex]@article{ferreiradasilva-fgcs-2013, title = {Self-healing of workflow activity incidents on distributed computing infrastructures}, journal = {Future Generation Computer Systems}, volume = {29}, number = {8}, pages = {2284--2294}, year = {2013}, doi = {10.1016/j.future.2013.06.012}, author = {Ferreira da Silva, Rafael and Glatard, Tristan and Desprez, Fr\'{e}d\'{e}ric} } -
Ferreira da Silva, R., Juve, G., Deelman, E., Glatard, T., Desprez, F., Thain, D., Tovar, B., & Livny, M. (2013). Toward fine-grained online task characteristics estimation in scientific workflows. 8th Workshop on Workflows in Support of Large-Scale Science, 58–67. https://doi.org/10.1145/2534248.2534254
[BibTex]@inproceedings{ferreiradasilva-works-2013, author = {Ferreira da Silva, Rafael and Juve, Gideon and Deelman, Ewa and Glatard, Tristan and Desprez, Fr{\'e}d{\'e}ric and Thain, Douglas and Tovar, Benjamin and Livny, Miron}, title = {Toward fine-grained online task characteristics estimation in scientific workflows}, booktitle = {8th Workshop on Workflows in Support of Large-Scale Science}, series = {WORKS '13}, year = {2013}, pages = {58--67}, doi = {10.1145/2534248.2534254} } -
Glatard, T., Lartizien, C., Gibaud, B., Ferreira da Silva, R., Forestier, G., Cervenansky, F., Alessandrini, M., Benoit-Cattin, H., Bernard, O., Camarasu-Pop, S., Cerezo, N., Clarysse, P., Gaignard, A., Hugonnard, P., Liebgott, H., Marache, S., Marion, A., Montagnat, J., Tabary, J., & Friboulet, D. (2013). A Virtual Imaging Platform for Multi-Modality Medical Image Simulation. IEEE Transactions on Medical Imaging, 32(1), 110–118. https://doi.org/10.1109/TMI.2012.2220154
[BibTex]@article{glatard-tmi-2013, author = {Glatard, T. and Lartizien, C. and Gibaud, B. and Ferreira da Silva, R. and Forestier, G. and Cervenansky, F. and Alessandrini, M. and Benoit-Cattin, H. and Bernard, O. and Camarasu-Pop, S. and Cerezo, N. and Clarysse, P. and Gaignard, A. and Hugonnard, P. and Liebgott, H. and Marache, S. and Marion, A. and Montagnat, J. and Tabary, J. and Friboulet, D.}, journal = {IEEE Transactions on Medical Imaging}, title = {A Virtual Imaging Platform for Multi-Modality Medical Image Simulation}, year = {2013}, volume = {32}, number = {1}, pages = {110--118}, doi = {10.1109/TMI.2012.2220154} }
2012
-
Ferreira da Silva, R., Glatard, T., & Desprez, F. (2012). Self-Healing of Operational Workflow Incidents on Distributed Computing Infrastructures. 12th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing, 318–325. https://doi.org/10.1109/CCGrid.2012.24
[BibTex]@inproceedings{ferreiradasilva-ccgrid-2012, author = {Ferreira da Silva, Rafael and Glatard, Tristan and Desprez, Fr\'ed\'eric}, booktitle = {12th {IEEE/ACM} International Symposium on Cluster, Cloud and Grid Computing}, series = {CCGrid'12}, title = {Self-Healing of Operational Workflow Incidents on Distributed Computing Infrastructures}, year = {2012}, pages = {318--325}, doi = {10.1109/CCGrid.2012.24} } -
Glatard, T., Marion, A., Benoit-Cattin, H., Camarasu-Pop, S., Clarysse, P., Ferreira da Silva, R., Forestier, G., Gibaud, B., Lartizien, C., Liebgott, H., Moulin, K., & Friboulet, D. (2012). Multi-modality image simulation with the Virtual Imaging Platform: Illustration on cardiac echography and MRI. 9th IEEE International Symposium on Biomedical Imaging, 98–101. https://doi.org/10.1109/ISBI.2012.6235493
[BibTex]@inproceedings{glatard-isbi-2012, author = {Glatard, T. and Marion, A. and Benoit-Cattin, H. and Camarasu-Pop, S. and Clarysse, P. and Ferreira da Silva, R. and Forestier, G. and Gibaud, B. and Lartizien, C. and Liebgott, H. and Moulin, K. and Friboulet, D.}, booktitle = {9th {IEEE} International Symposium on Biomedical Imaging}, series = {ISBI}, title = {Multi-modality image simulation with the Virtual Imaging Platform: Illustration on cardiac echography and MRI}, year = {2012}, pages = {98--101}, doi = {10.1109/ISBI.2012.6235493} }
2011
-
Brasileiro, F., Gaudencio, M., Ferreira da Silva, R., Duarte, A., Carvalho, D., Scardaci, D., Ciuffo, L., Mayo, R., Hoeger, H., Stanton, M., Ramos, R., Barbera, R., Marechal, B., & Gavillet, P. (2011). Using a Simple Prioritisation Mechanism to Effectively Interoperate Service and Opportunistic Grids in the EELA-2 e-Infrastructure. Journal of Grid Computing, 9(2), 241–257. https://doi.org/10.1007/s10723-010-9177-5
[BibTex]@article{brasileiro-jogc-2011, year = {2011}, journal = {Journal of Grid Computing}, volume = {9}, issue = {2}, doi = {10.1007/s10723-010-9177-5}, title = {Using a Simple Prioritisation Mechanism to Effectively Interoperate Service and Opportunistic Grids in the EELA-2 e-Infrastructure}, author = {Brasileiro, Francisco and Gaudencio, Matheus and Ferreira da Silva, Rafael and Duarte, Alexandre and Carvalho, Diego and Scardaci, Diego and Ciuffo, Leandro and Mayo, Rafael and Hoeger, Herbert and Stanton, Michael and Ramos, Raul and Barbera, Roberto and Marechal, Bernard and Gavillet, Philippe}, pages = {241--257} } -
Ferreira da Silva, R., Camarasu-Pop, S., Grenier, B., Hamar, V., Manset, D., Montagnat, J., Revillard, J., Rojas Balderrama, J., Tsaregorodtsev, A., & Glatard, T. (2011). Multi-infrastructure workflow execution for medical simulation in the Virtual Imaging Platform. 2011 HealthGrid Conference.
[BibTex]@inproceedings{ferreiradasilva-healthgrid-2011, author = {Ferreira da Silva, Rafael and Camarasu-Pop, Sorina and Grenier, Baptiste and Hamar, Vanessa and Manset, David and Montagnat, Johan and Revillard, J\'er\^ome and Rojas Balderrama, Javier and Tsaregorodtsev, Andrei and Glatard, Tristan}, booktitle = {2011 HealthGrid Conference}, title = {Multi-infrastructure workflow execution for medical simulation in the Virtual Imaging Platform}, year = {2011} } -
Marion, A., Forestier, G., Benoit-Cattin, H., Camarasu-Pop, S., Clarysse, P., Ferreira da Silva, R., Gibaud, B., Glatard, T., Hugonnard, P., Lartizien, C., Liebgott, H., Specovius, S., Tabary, J., Valette, S., & Friboulet, D. (2011). Multi-modality medical image simulation of biological models with the Virtual Imaging Platform (VIP). 2011 24th International Symposium on Computer-Based Medical Systems, 1–6. https://doi.org/10.1109/CBMS.2011.5999141
[BibTex]@inproceedings{marion-cbms-2011, author = {Marion, A. and Forestier, G. and Benoit-Cattin, H. and Camarasu-Pop, S. and Clarysse, P. and Ferreira da Silva, R. and Gibaud, B. and Glatard, T. and Hugonnard, P. and Lartizien, C. and Liebgott, H. and Specovius, S. and Tabary, J. and Valette, S. and Friboulet, D.}, booktitle = {2011 24th International Symposium on Computer-Based Medical Systems}, series = {CBMS}, title = {Multi-modality medical image simulation of biological models with the Virtual Imaging Platform (VIP)}, year = {2011}, pages = {1--6}, doi = {10.1109/CBMS.2011.5999141} }
2010
-
Ferreira da Silva, R., Brasileiro, F., & Lopes, R. (2010). Provendo Eficiência e Justiça em um Sistema de Cache em Disco para Grades Computacionais Entre-Pares. 28th Brazilian Symposium on Computer Networks and Distributed Systems (SBRC), 321–334.
[BibTex]@inproceedings{ferreiradasilva-sbrc-2010, title = {Provendo Efici\^encia e Justiça em um Sistema de Cache em Disco para Grades Computacionais Entre-Pares}, author = {Ferreira da Silva, Rafael and Brasileiro, Francisco and Lopes, Raquel}, booktitle = {28th Brazilian Symposium on Computer Networks and Distributed Systems ({SBRC})}, year = {2010}, pages = {321--334} }
2009
-
Brasileiro, F., Duarte, A., Ferreira da Silva, R., & Gaudêncio, M. (2009). On the co-existence of service and opportunistic grids. First EELA-2 Conference, 51–62.
[BibTex]@inproceedings{brasileiro-eela2-2009, title = {On the co-existence of service and opportunistic grids}, author = {Brasileiro, Francisco and Duarte, Alexandre and Ferreira da Silva, Rafael and Gaud{\^e}ncio, Matheus}, booktitle = {First EELA-2 Conference}, year = {2009}, pages = {51--62} }
2007
-
Pires, S., Ferreira da Silva, R., & Mongiovi, G. (2007). Lupa: Um Ambiente Facilitador de Desenvolvimento de Aplicações Data Mining. IV Simpósio Mineiro De Sistemas De Informação (SMSI), 1–8.
[BibTex]@inproceedings{pires-smsi-2007, title = {Lupa: Um Ambiente Facilitador de Desenvolvimento de Aplica\c{c}\~oes Data Mining}, author = {Pires, St\'efani and Ferreira da Silva, Rafael and Mongiovi, Giuseppe}, booktitle = {IV Simp\'osio Mineiro de Sistemas de Informa\c{c}\~ao ({SMSI})}, year = {2007}, pages = {1--8} }
Professional Activities
Editor, chair, program committee member, reviewer
Journals Editor
2023-present
Special Content Editor
2019–2024
Associate Editor
2020-2023
2023
Co-Guest Editor
2018
Co-Guest Editor
Chair Roles in Conferences
Served in chair roles in 20 conferences
2024
SC - IEEE/ACM The International Conference for High Performance Computing, Networking, Storage, and Analysis
Track Chair: Data Analytics, Visualization, & Storage — SC, USA2023
2022
2021
2019
eScience - IEEE eScience Conference
Program Chair — 19th eScience, Limassol, CyprusPublicity and Web Chair — 18th eScience, Salt Lake City, USA
Publicity Chair — 17th eScience, Innsbruck, Austria
Track Chair: Software Tools & Infrastructure — 15th eScience, San Diego, USA
2024
2023
2022
2021
2020
2019
2018
2017
2016
WORKS - IEEE Workflows in Support of Large-Scale Science Workshop
Program Chair — 17th WORKS, Dallas, USAProgram Chair — 16th WORKS, Saint-Louis, USA
Program Chair — 15th WORKS, Atlanta, USA
Program Chair — 14th WORKS, Denver, USA
Program Chair — 13th WORKS, Dallas, USA
Publicity Chair — 12th WORKS, Denver, USA
Publicity Chair — 11th WORKS, Salt Lake City, USA
2023
2016
SBAC-PAD - IEEE International Symposium on Computer Architecture and High Performance Computing
Track Chair: Performance Evaluation — 35th SBAC-PAD, Porto Alegre, BrazilLocal Arrangements Chair — 28th SBAC-PAD, Los Angeles, USA
2022
ERROR - Workshop on E-science ReseaRch leading tO negative ResultsWorkshop
Program Chair — 2nd ERROR, Salt Lake City, USA2022
Gateways - Gateways 2022
Publication Chair — Gateways, San Diego, CA, USA2019
BC2DC - Bridging from Concepts to Data and Computation for eScience Workshop
Program Chair — 1st BC2DC, San Diego, CA2018
NSF SI2 PI Meeting - Software Infrastructure for Sustained Innovation Principal Investigator Workshop
Organizer — NSF SI2 PI Meeting, Washington D.C., USAProgram Committees Member
Served as PC member in 52 conferences
2024
2023
2022
2024
2023
2019
2023
2021
2023
Euro-Par - International European Conference on Parallel and Distributed Computing
29th Euro-Par, Limassol, Cyprus2023
2021
2019
2018
2017
2023
2022
2017
2016
2015
CCGrid - IEEE/ACM International Symposium on Cluster, Cloud and Internet Computing
23rd CCGrid, Bangalore, India22nd CCGrid, Taormina, Italy
17th CCGrid, Madrid, Spain
16th CCGrid, Cartagena, Colombia
15th CCGrid, Shenzhen, China
2023
CLOUD - IEEE International Conference on Cloud Computing
CLOUD, Chicago, USA2022
2021
IPDPS - IEEE International Parallel & Distributed Processing Symposium
36th IPDPS, Lyon, France35th IPDPS, Portland, USA
2022
2021
2019
2018
2017
2016
SBAC-PAD - IEEE International Symposium on Computer Architecture and High Performance Computing
34th SBAC-PAD, Bordeaux, France33rd SBAC-PAD, Belo Horizonte, Brazil
31st SBAC-PAD, Campo Grande, Brazil
30th SBAC-PAD, Lyon, France
29th SBAC-PAD, Campinas, Brazil
28th SBAC-PAD, Los Angeles, USA
2022
PASC - Platform for Advanced Scientific Computing
PASC, Basel, Switzerland2024
2023
2020
2019
2018
2017
2016
WORKS - Workflows in Support of Large-Scale Science
15th WORKS, Atlanta, USA14th WORKS, Denver, USA
13th WORKS, Dallas, USA
12th WORKS, Denver, USA
11th WORKS, Salt Lake City, USA
2021
2020
2019
2018
2017
2016
2015
2014
CloudAM - IEEE/ACM International Workshop on Clouds and Edge Computing, and Applications Management
10th CloudAM, Leicester, UK9th CloudAM, Leicester, UK
8th CloudAM, Auckland, New Zealand
7th CloudAM, Zurich, Switzerland
6th CloudAM, Austin, USA
5th CloudAM, Shanghai, China
4th CloudAM, Limassol, Cyprus
3rd CloudAM, London, UK
2021
HPCMASPA - Workshop on Monitoring and Analysis for HPC Systems Plus Applications
HPCMASPA, Portland, USA2022
2021
ReWorDS - Workshop on Reproducible Workflows, Data Management, and Security
2nd ReWorDS, Salt Lake City, USA1st ReWorDS, Innsbruck, Austria
2021
HiPS - Workshop on High Performance Serverless Computing
1st HiPS, Stockholm, Sweden2020
ICDCS - IEEE International Conference on Distributed Computing Systems
40th ICDCS, Singapore2018
2017
2016
RepScience - International Workshop on Reproducible Open Science
1st RepScience, Hannover, GermanyFunding Agencies Reviewer
2024
2023
2021
DOE - U.S. Department of Energy
Mail In Reviews, ASCRMail In Reviews, ASCR
Mail In Reviews, ASCR
2024
2023
2022
2021
2020
2019
2018
2017
NSF - U.S. National Science Foundation
Virtual Review Panel, OACVirtual Review Panel, OAC
Virtual Review Panels, OAC
Virtual Review Panels and Ad-hoc Reviewer, OAC
Review Panel and Ad-hoc Reviewer, OAC
Review Panels and Ad-hoc Reviewer, OAC
Review Panels, OAC
Review Panels, OAC
2020
ARO - U.S. Army Research Office
Ad-hoc Reviewer2019
NWO - Netherlands Organisation for Scientific Research
Ad-hoc ReviewerSteering Committees
2023-present
IEEE eScience Conference
Member
Professional Associations
Institute of Electrical and Electronics Engineers (IEEE)
2017—2022: Member

Association for Computing Machinery (ACM)
2018—2023: Member
Funding Awards
Research grants and collaborations
U.S. Department of Energy (DOE)
04/2023-04/2024
Center for Sustaining Workflows and Application Services
$120,000 — Advanced Scientific Computing Research (ASCR)
2017-12/2023
ExaWorks: ECP Workflows Project
$3,773,833 — Exascale Computing Project
U.S. National Science Foundation (NSF)
10/2021-09/2024
Collaborative Research: OAC Core: Simulation-driven runtime resource management for distributed workflow applications
$499,988 — Computer and Information Science and Engineering (CISE): Core Programs
#2106059
#2106147
08/2021-07/2024
Collaborative Research: Elements: Simulation-driven Evaluation of Cyberinfrastructure Systems
$600,000 — Software Institutes (CSSI)
#2103489
#2103508
05/2021-10/2022
Collaborative Research: EAGER: VisDict - Visual Dictionaries for Enhancing the Communication between Domain Scientists and Scientific Workflow Providers
$264,500 — Computing and Communication Foundations (CCF)
#2100561
#2100636
03/2021-02/2024
REU Site: SURF-I: Safe, Usable, Resilient and Fair Internet
$405,000 — Computer and Network Systems (CNS)
#2051101
10/2020-09/2021
CCRI: Planning: Collaborative Research: Infrastructure for Enabling Systematic Development and Research of Scientific Workflow Management Systems
$100,000 — CISE Community Research Infrastructure
#2016610
#2016619
#2016682
10/2020-09/2021
Collaborative Research: PPoSS: Planning: Performance Scalability, Trust, and Reproducibility: A Community Roadmap to Robust Science in High-throughput Applications
$250,000 — Scalable Parallelism in the Extreme (SPX)
#2028881
#2028923
#2028930
#2028955
#2028956
10/2019–09/2022
Collaborative Research: CyberTraining: Implementation: Small: Integrating core CI literacy and skills into university curricula via simulation-driven activities
$500,000 — CyberTraining – Training-based
#1923539
#1923621
10/2018–09/2021
Coordinating Curricula and User Preferences to Increase the Participation of Women and Students of Color in Engineering
$300,000 — IUSE
#1826632
10/2017–09/2021
BIGDATA: IA: Collaborative Research: In Situ Data Analytics for Next Generation Molecular Dynamics Workflows
$1,993,043 — Big Data Science & Engineering
#1741057
#1740990
#1741040
01/2017—12/2019
Collaborative Research: SI2-SSE: WRENCH: A Simulation Workbench for Scientific Workflow for Users, Developers, and Researchers
$497,956 — Software Institutes
#1642369
#1642335
06/2018–05/2019
2018 Software Infrastructure for Sustained Innovation (SI2) Principal Investigators Workshop
$85,065 — Software Institutes
#1831393
U.S. Defense Advanced Research Projects Agency (DARPA)
12/2017–11/2021
MINT: Model INTegration through Knowledge-Rich Data and Process Composition
$12,979,881 — World Modelers
#W911NF-18-1-0027
International Funding / Collaborations / Others
08/2021 – 05/2022
Integrating Cyberinfrastructure Literacy into University Curricula
$4,400 — USC URAP
08/2020 – 05/2021
Teaching Parallel and Distributed Computing Concepts in Simulation
$3,300 — USC URAP
08/2019 – 05/2020
Integrating core CI literacy and skills into university curricula via simulation-driven activities
$2,825 — USC URAP
1/2016–12/2018
Laboratoire Virtuel pour la Conception de Systèmes de Gestion de Workflows
24,000 € — CNRS PICS (France)
#PICS07239